



Transcript
Noonan: Choosing to move to a microservices architecture is something that almost every engineering team is seduced by at some point, no matter what size of company or product you have. There's so much content out there warning you about the trade-offs, but your developer productivity is declining due to the fault isolation and modularity that come inherently with a monolith. However, if they are implemented incorrectly or used as a Band-Aid without addressing some of the root flaws in your system, you'll find yourself no longer to make any new product development because you'll be drowning in the complexity.
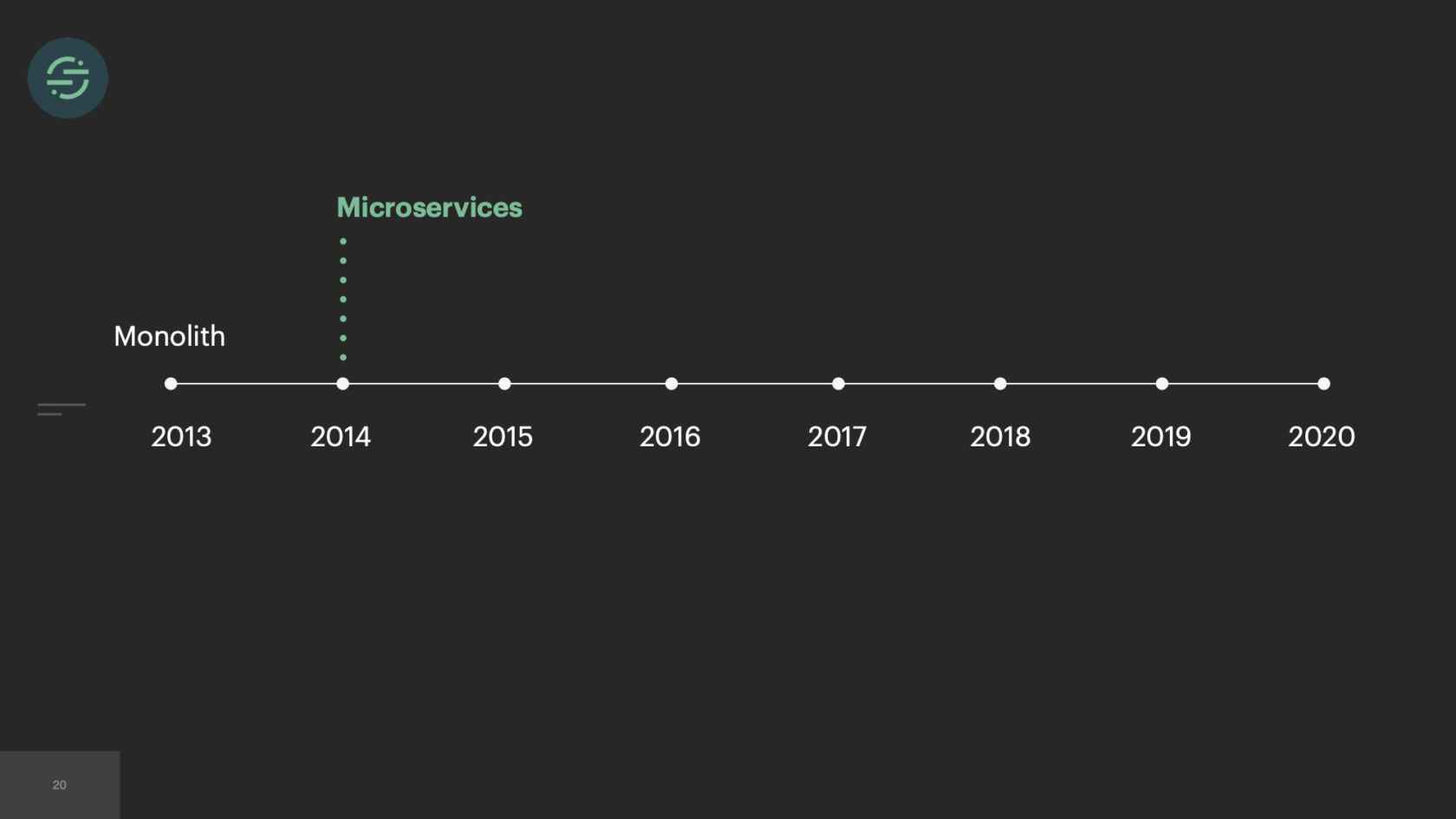
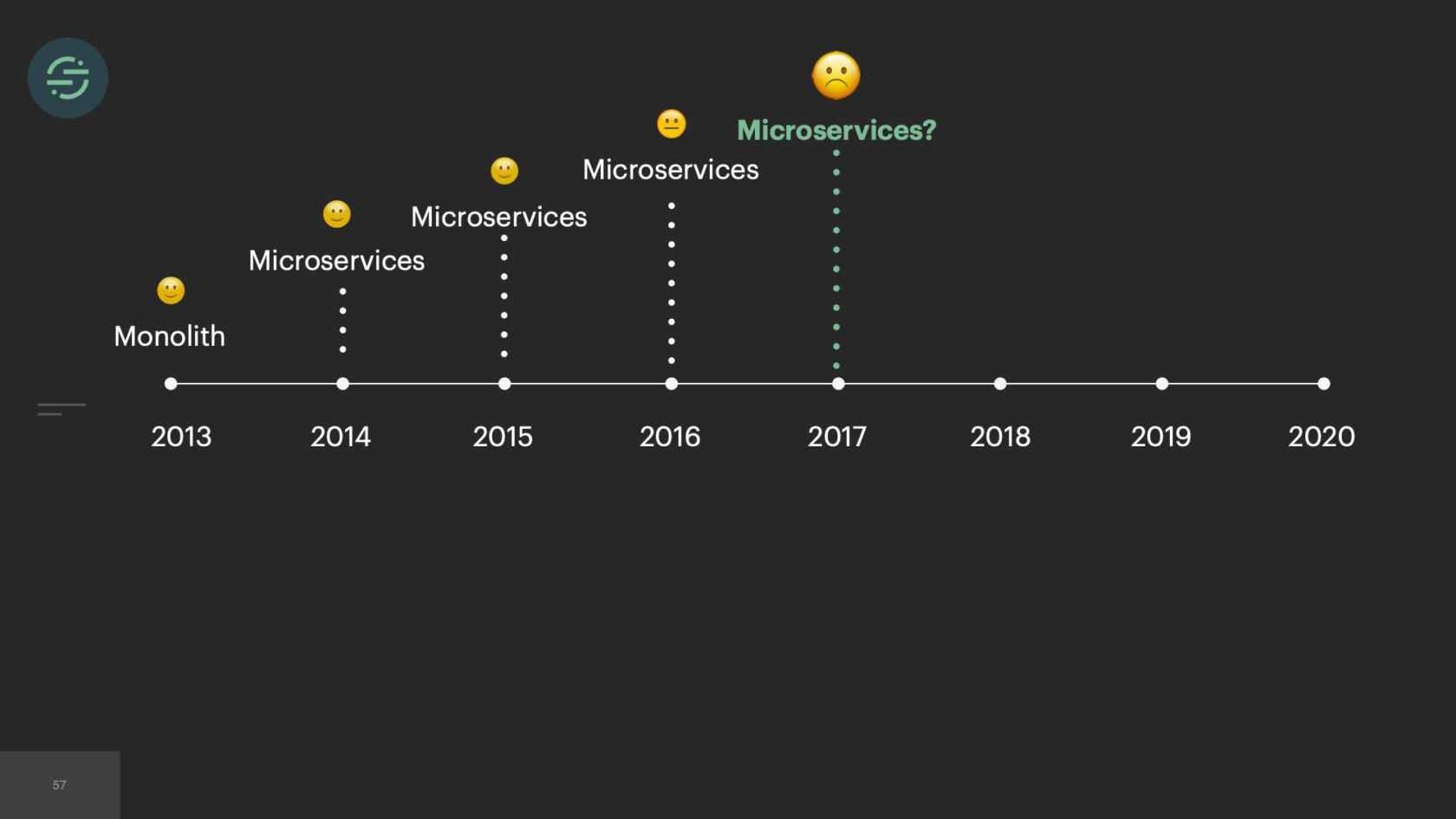
At Segment, we decided to break apart our monolith to microservices about a year after we launched. However, it failed to address some of the flaws in our systems. About three years of after continuing to add to our microservices, we were drowning in the complexity. In 2017, we took a step back and decided to move back to a monolith. The trade-offs that came with microservices caused more issues than they fixed. Moving back to a monolith is what allowed us to be able to fix some of the fundamental flaws in our system. My hope today is that you'll understand and learn to deeply consider the trade-offs that come with microservices, and make the decision that is right for your team.
What we're going to cover is I'll go over what Segment does to help give you some context on the infrastructure decisions that we made. I'll go over our basic monolithic architecture. Then why we moved to microservices, and why they worked for us in production for so long. Then I'll cover what led us to hit the tipping point and inspired us to move back to a monolith, and how we did that. Then as with every big infrastructure decision, there are always trade-offs. I'll cover the trade-offs that we dealt with moving back to a monolith and how we think about them moving forward.
What Does Segment Do?
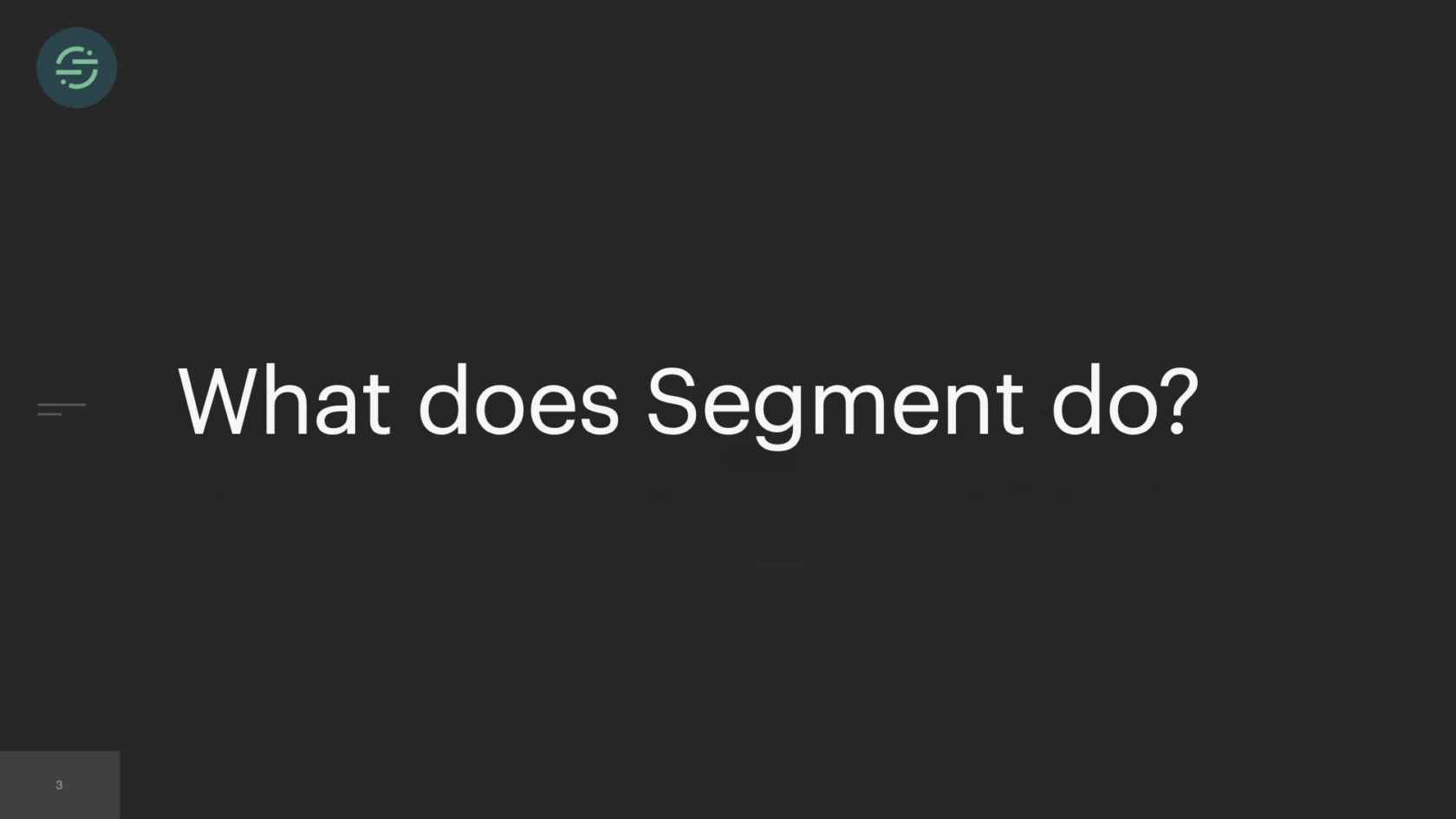
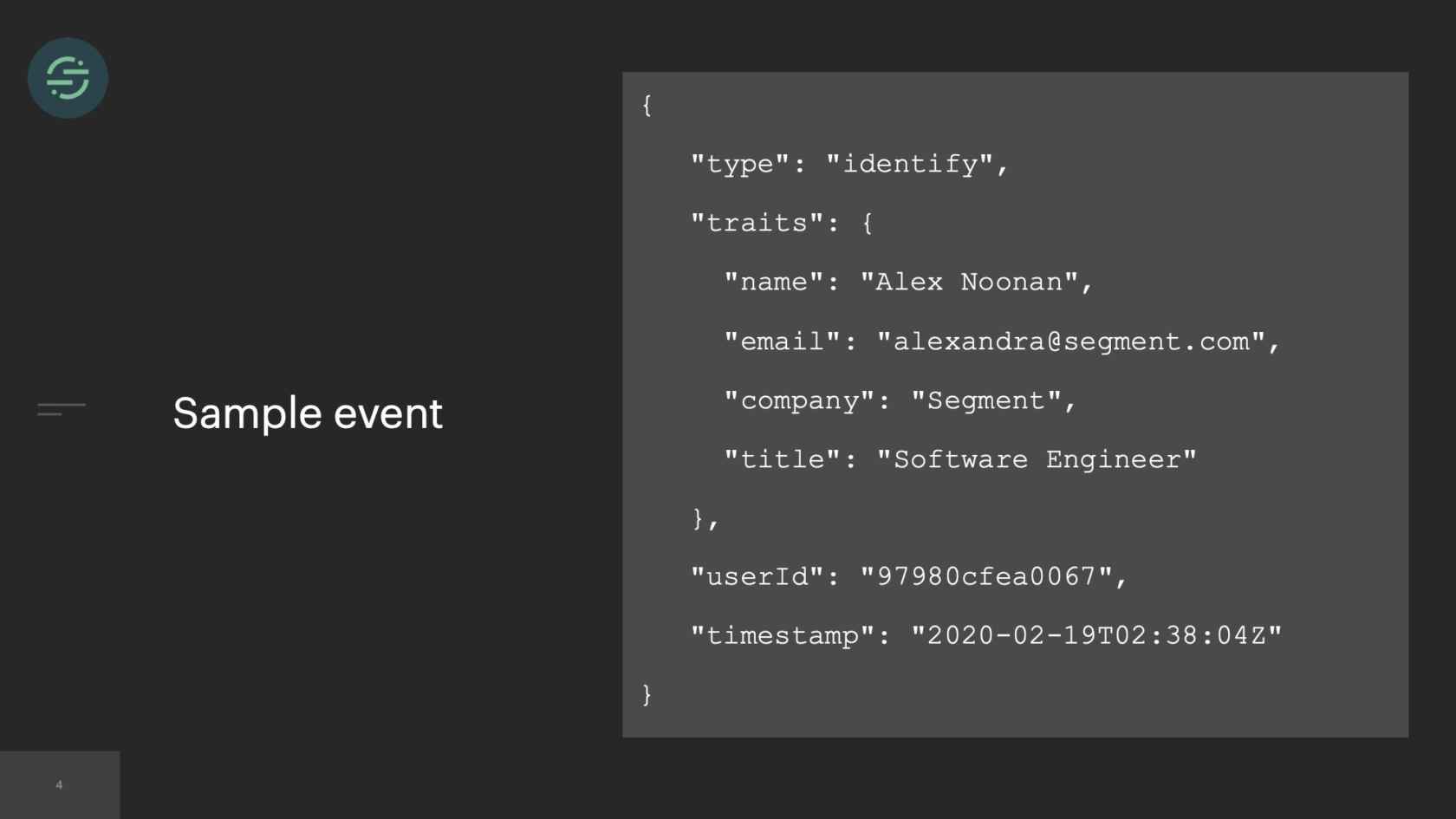
What Does Segment do? I'm assuming most of you don't know this, maybe some of you do. At Segment, we have a data pipeline. That data pipeline ingests hundreds of thousands of events per second. This is what a sample event looks like. It's a JSON payload that contains basic information about users and their actions. These events are generated by the software that our customers built. A lot of people build really great software, and they want to understand how their customers are using that software. There are a ton of great tools out there that let you do that. For example, Google has one called Google Analytics. If you want to get up and started with Google Analytics, you have to go and add code in every single piece of your product to start sending data to Google Analytics' API. Your marketing team maybe wants to use Mixpanel, your sales team wants to use Salesforce. Every time you want to add a new tool, you have to go in and write code in all the different sources of your product. Eventually, you could turn into something like this. It's basically this big mesh of sources and tools that you're sending your data to. Maybe one of them is leaking PII. The data is not consistent across tools. You want to try using a new tool, but you have to write code again in all of your sources to get started with that tool.
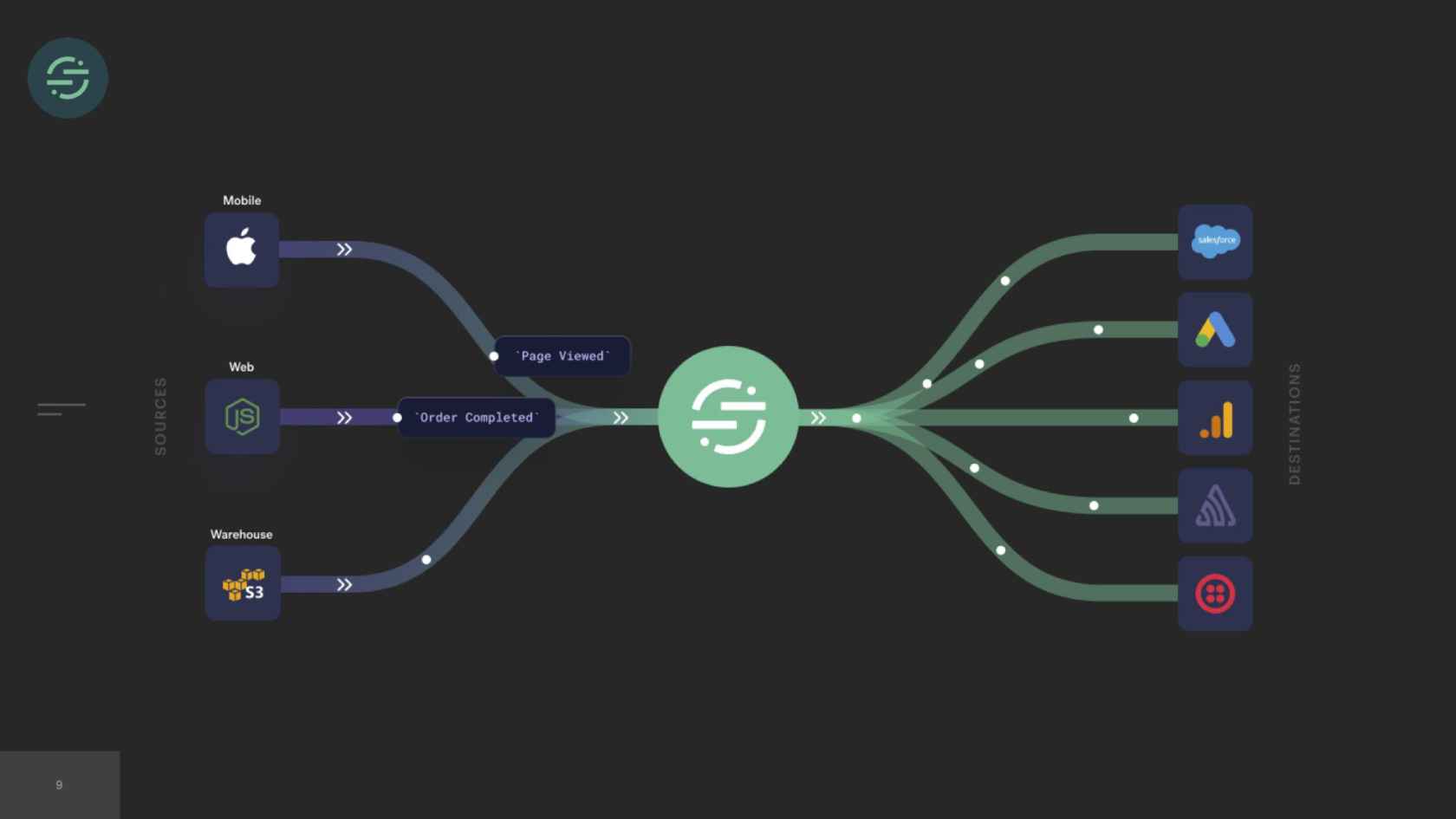
Segment's goal is to make that easier. We provide a single API that you could send your data to. Then we'll take care of sending your events to any end tool that you want. We have a single API. As a developer, you have to write significantly less code, because you just implement us once and then we handle sending that data for you. We provide tools along the way to help you do things such as strip any sensitive data or run any analysis on these tools. If you want to start using a new tool, it's as simple as just going into our app, and enabling that tool. The piece of our infrastructure that I'm going to focus on today is these end tools and the forwarding of events to those tools. We refer to these tools as destinations.
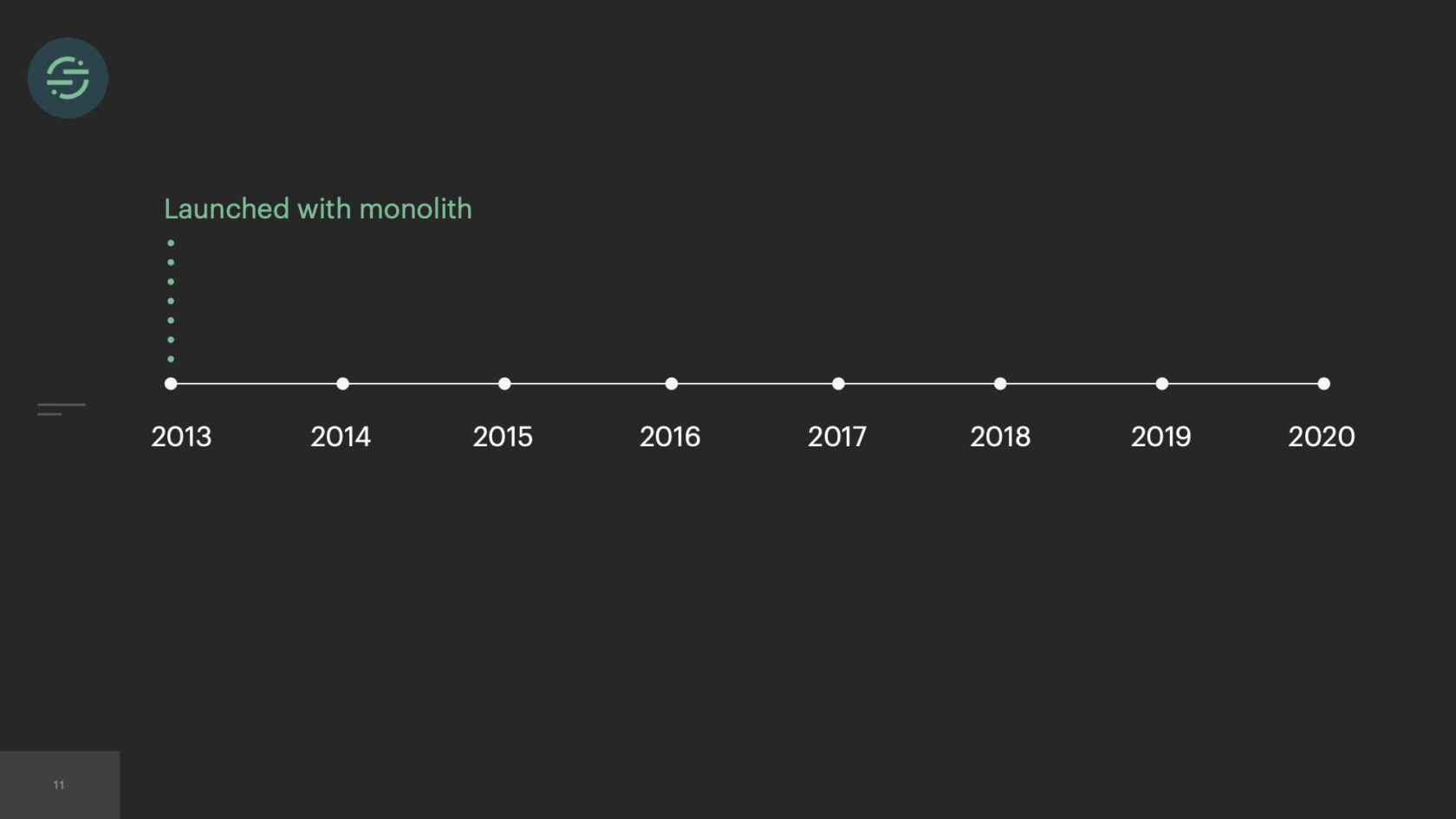
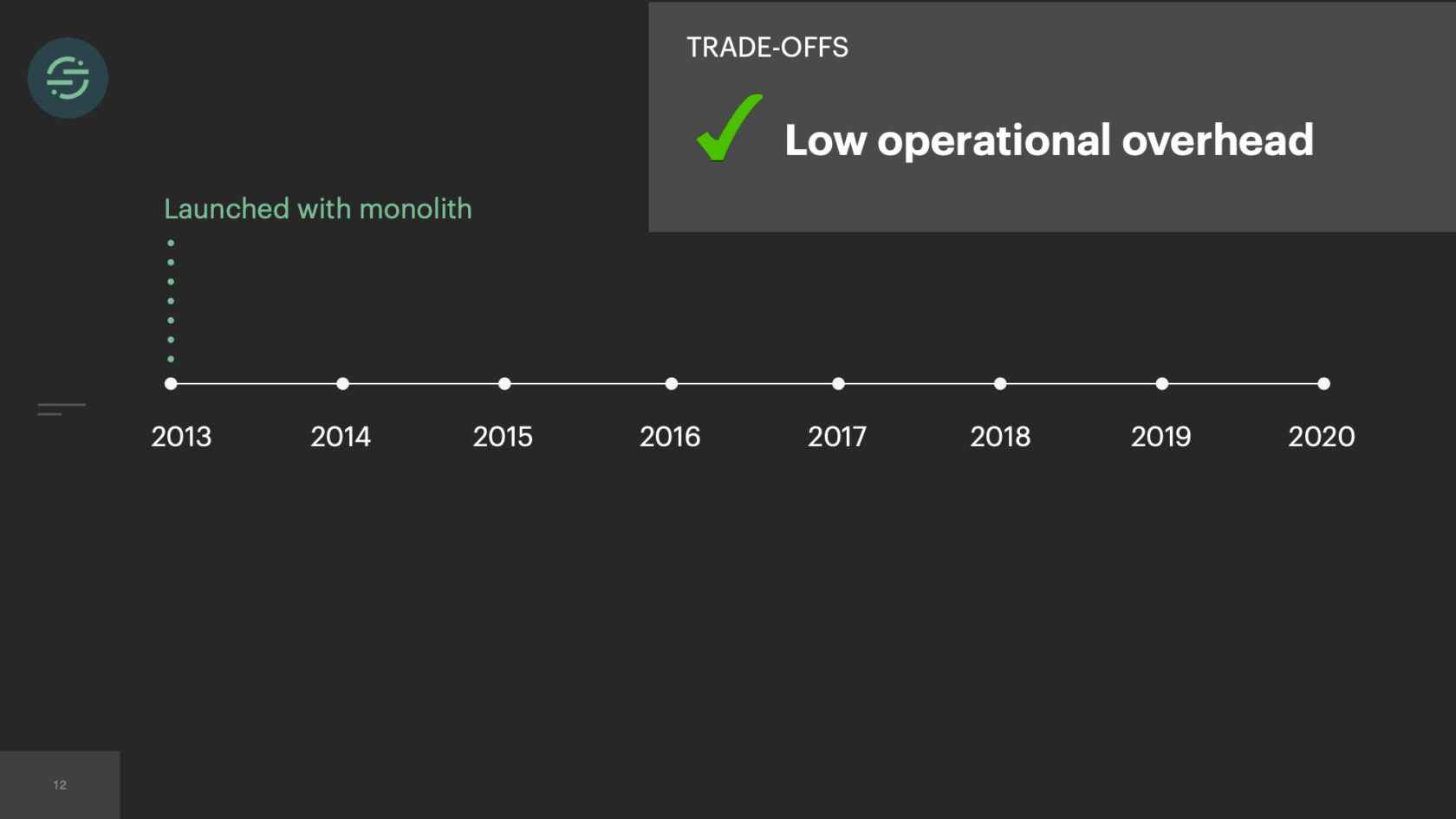
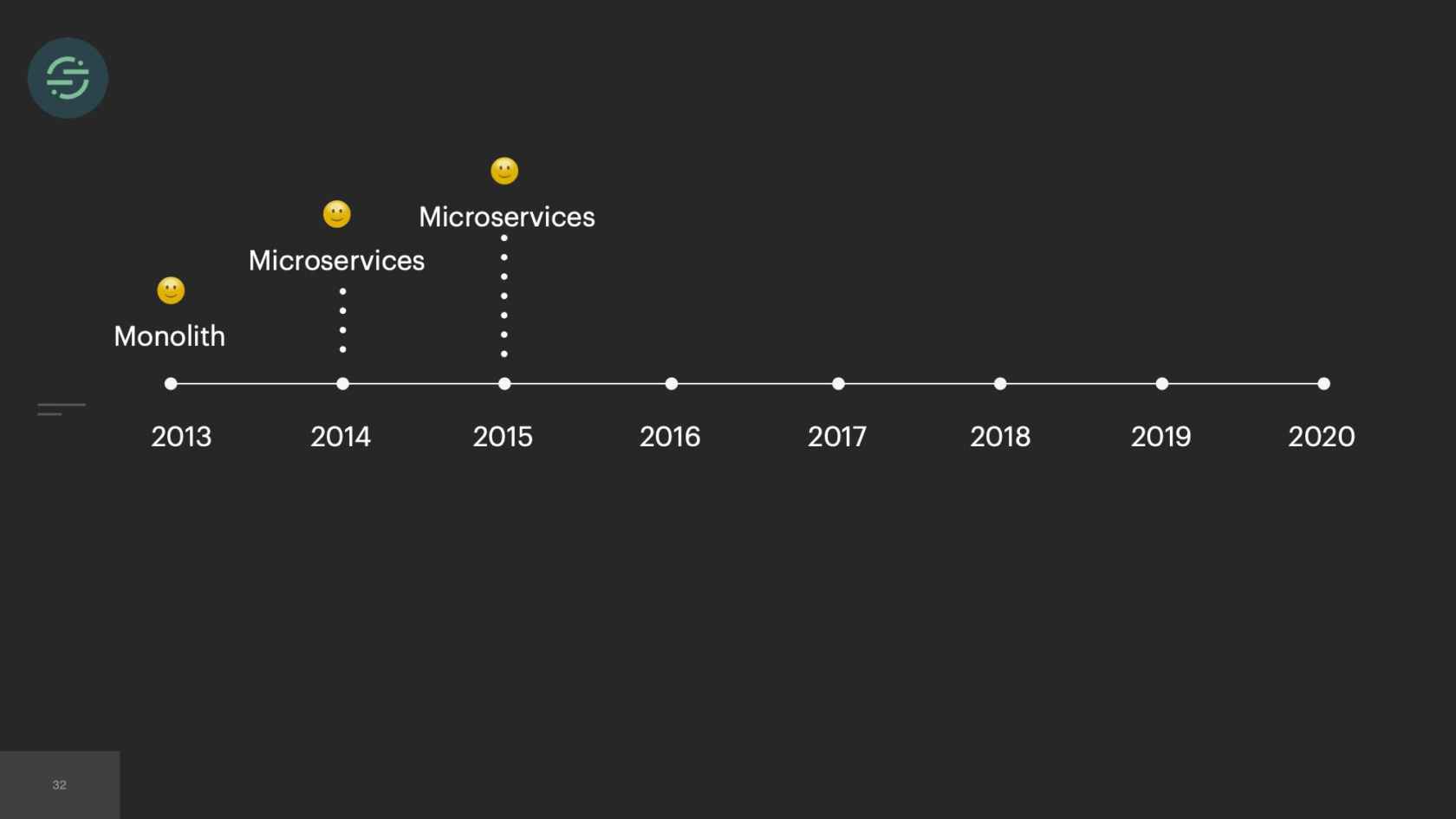
In 2013, when we first launched our product, we launched with a monolith. We needed the low operational overhead that came with managing a monolith. It was just our fore-founders, and they needed whatever infrastructure was easiest for them to move and iterate on.
Original Architecture
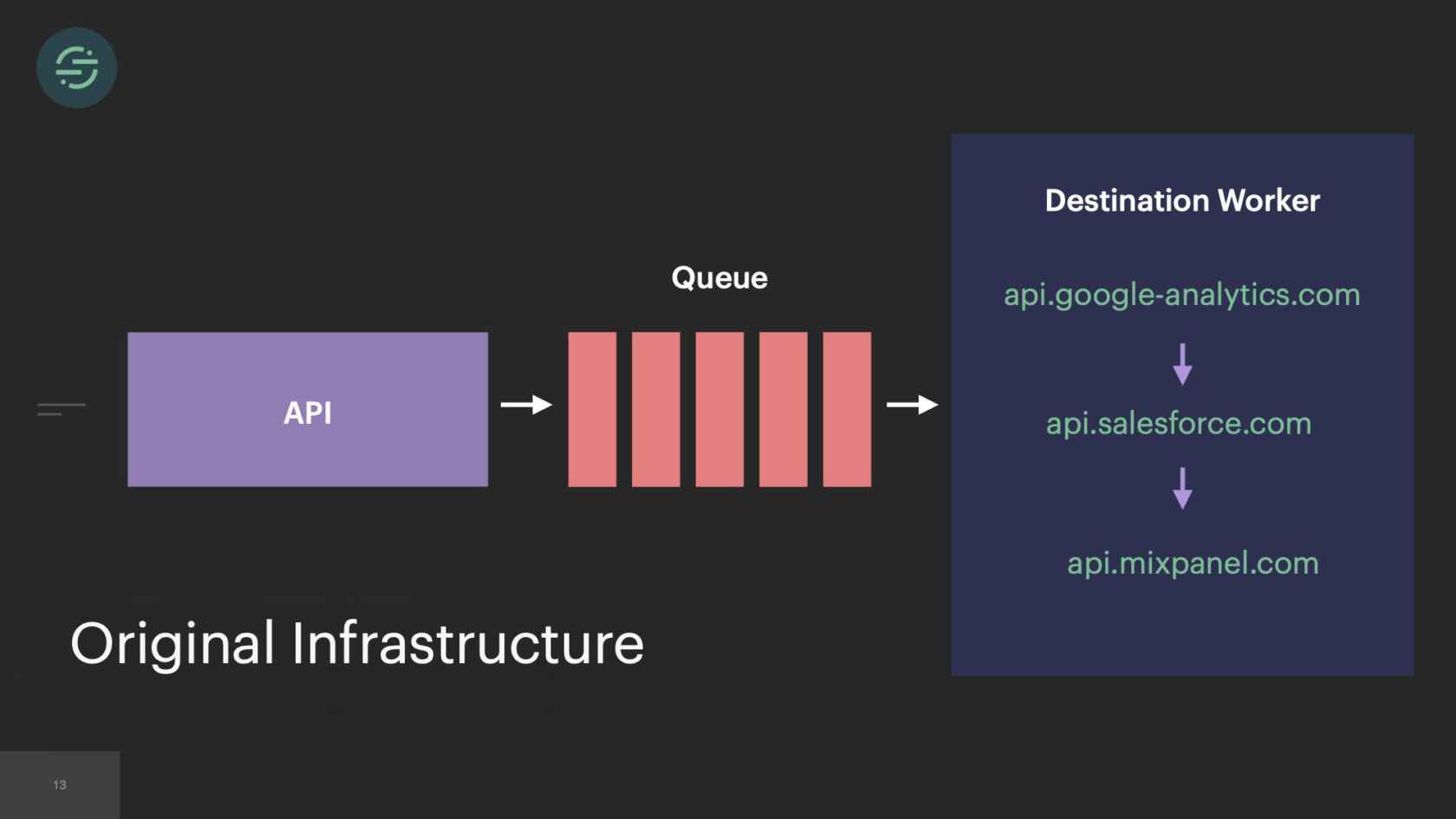
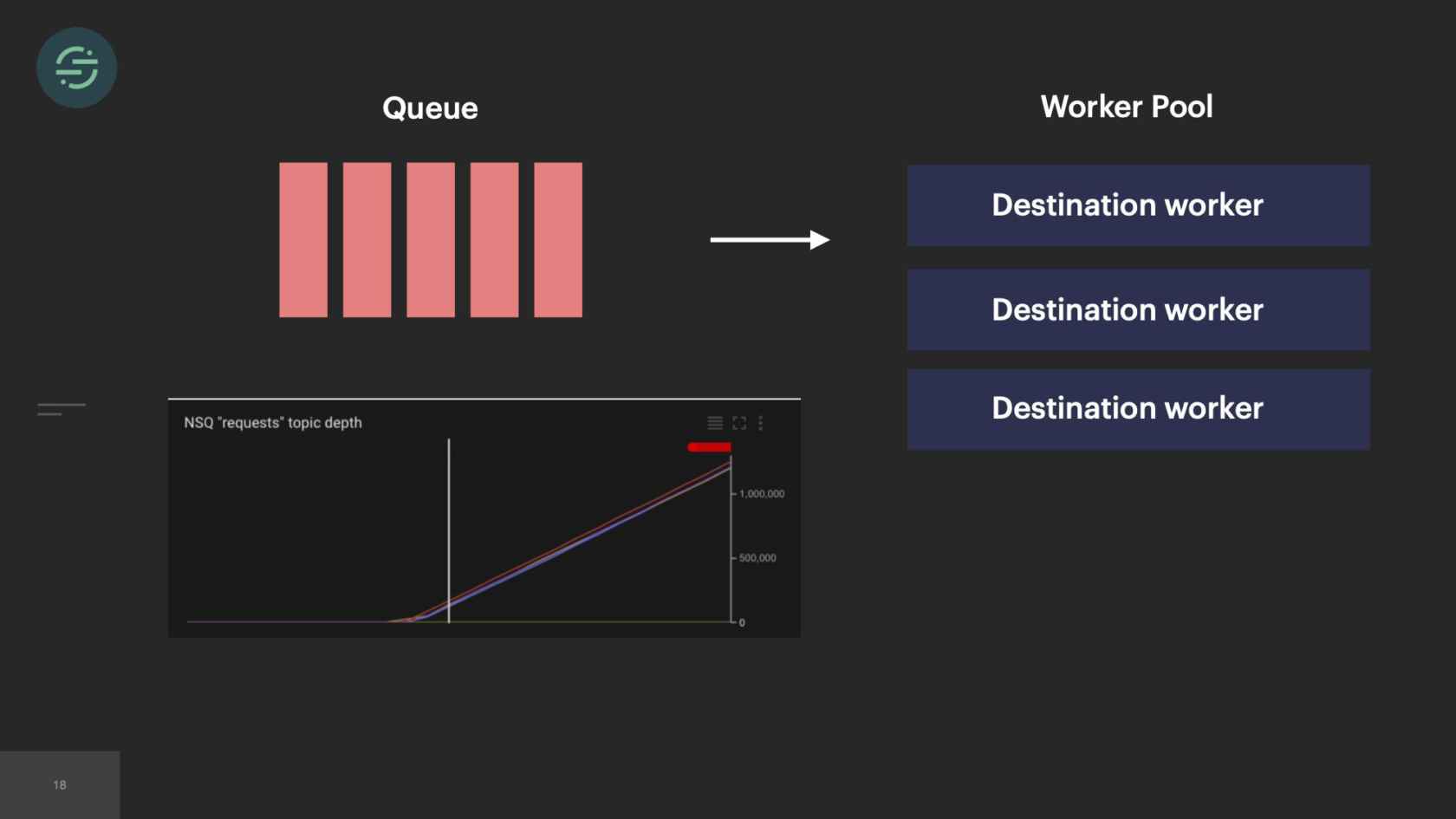
This was the original architecture. We had a single API that ingested events and forwarded them to a distributed message queue. Then there was a single monolithic destination worker at the end that consumed from this queue. Each one of these destination APIs expects events to be in a specific format. The destination worker would consume an event from the queue, check customer managed settings to see which destination the event needed to go to. It would then transform the event to be compatible with that destination API. Send them a request over the internet to that destination. Wait for the response back. Then move on to the next destination.
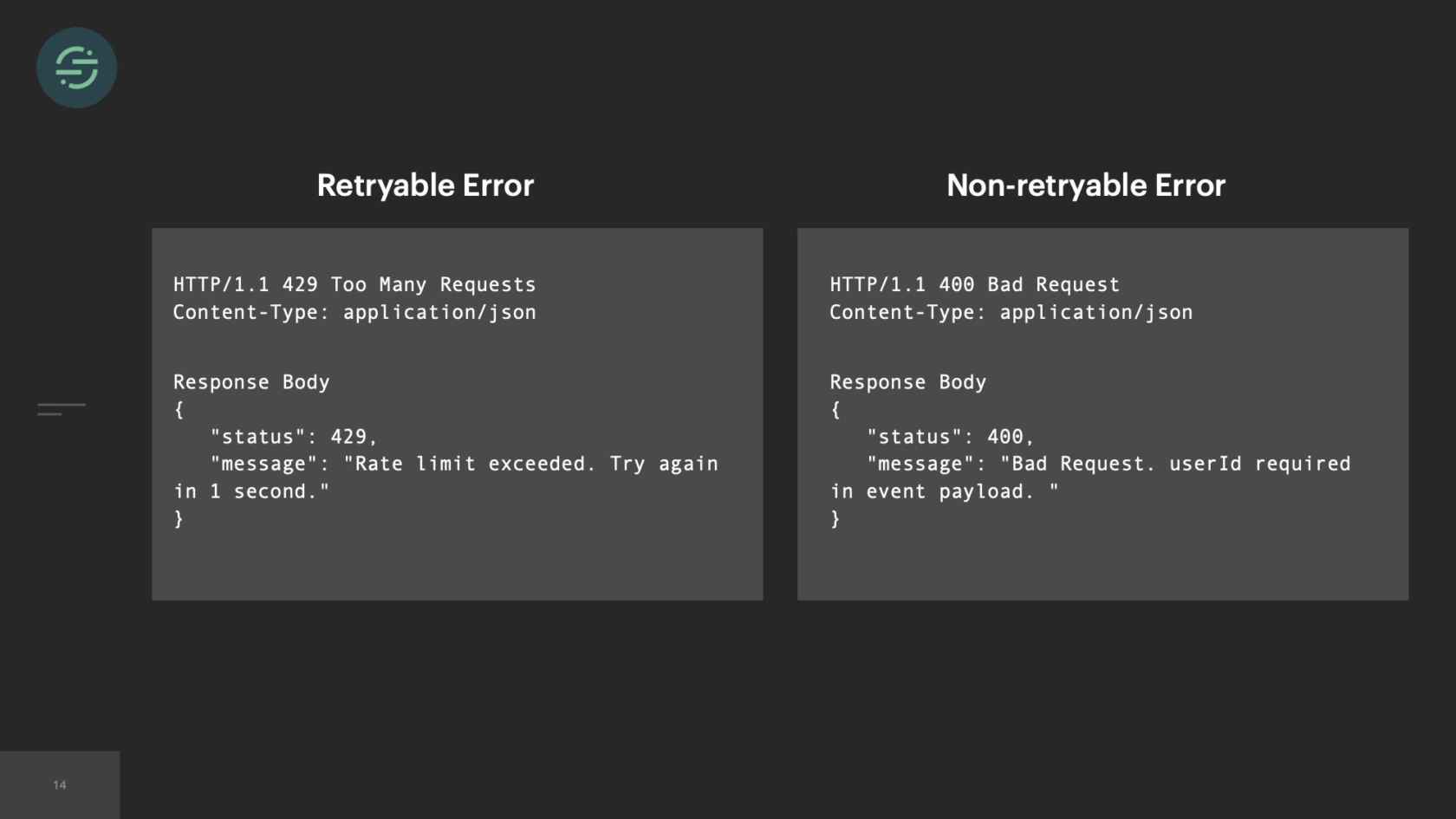
Requests to destination actually fail pretty frequently. We categorize those errors into two different types. There's a retryable error and a non-retryable error. A non-retryable error is something that we know will never be accepted by the destination API. This could be that you have invalid credentials or your event is missing a required field like a user ID, or an email. Then there are retryable errors. Retryable errors are something that we think could potentially be accepted later by the destination with no changes.
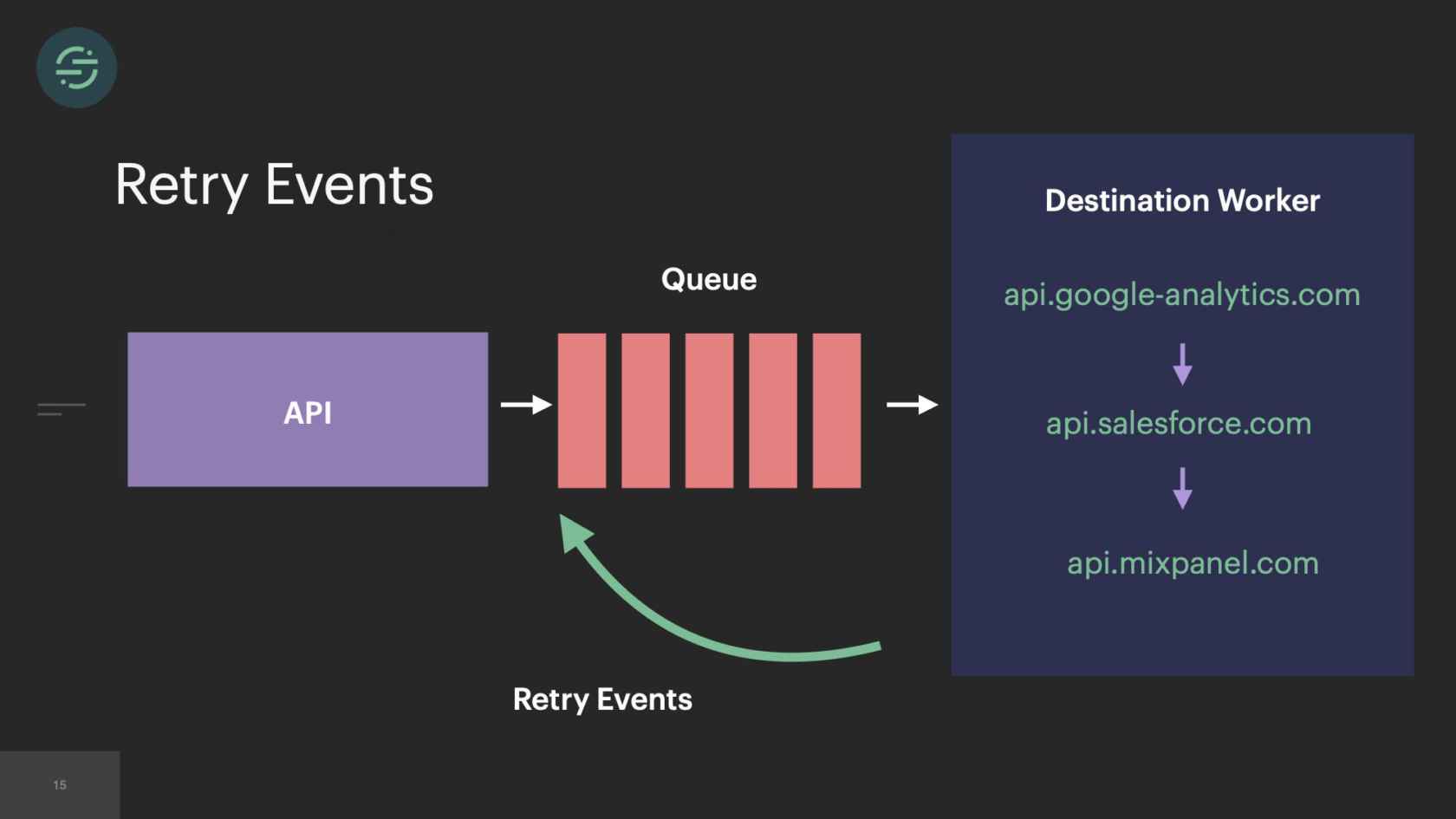
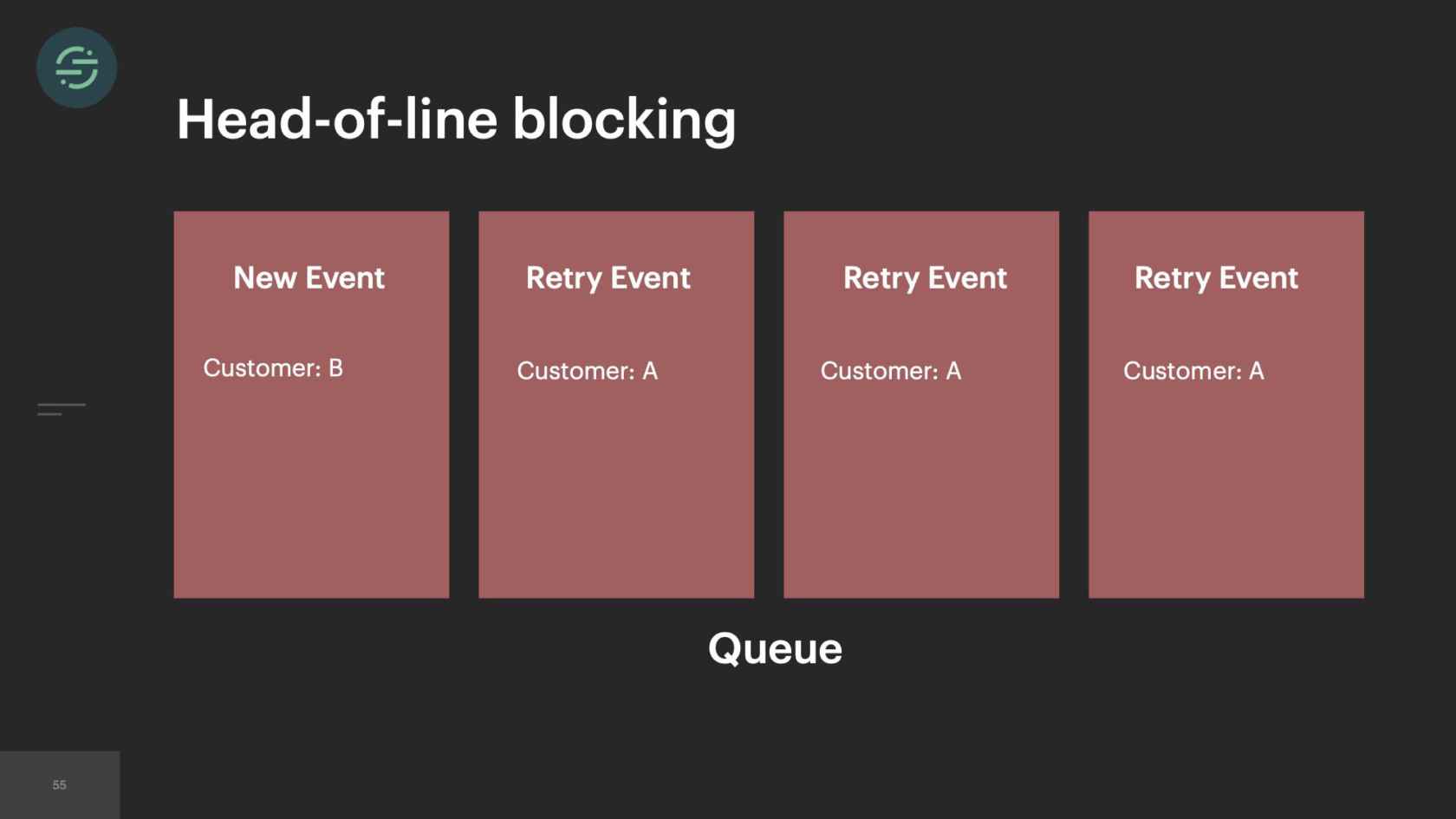
This is what retries looked like in our infrastructure. The destination worker would get a response back from the destination API. If it needed to be retried, it would put it back in the queue in line with everything else. We keep retrying events for a specific amount of time before giving up. It's usually anywhere from about 2 to 10 attempts. What this caused, though, is something called head-of-line blocking. Head-of-line blocking is a performance issue where things are blocked by whatever is first in line. This is first-in, first-out design. If you zoom in on our queue, in particular, you'll see we have the newest events in line with retry events across all our customers and all destinations.
What would happen is Salesforce, for example, is having a temporary outage. Every event sent to Salesforce fails and is put back in the queue to be sent again at a later time. We had auto-scaling at the time to add more workers to the pool to be able to handle this increase in queued up. This sudden flood would outpace our ability to scale up, which then resulted in delays across all our destinations for all of our customers. Customers rely on the timeliness of this data. We can't afford these types of delays anywhere in our pipeline.
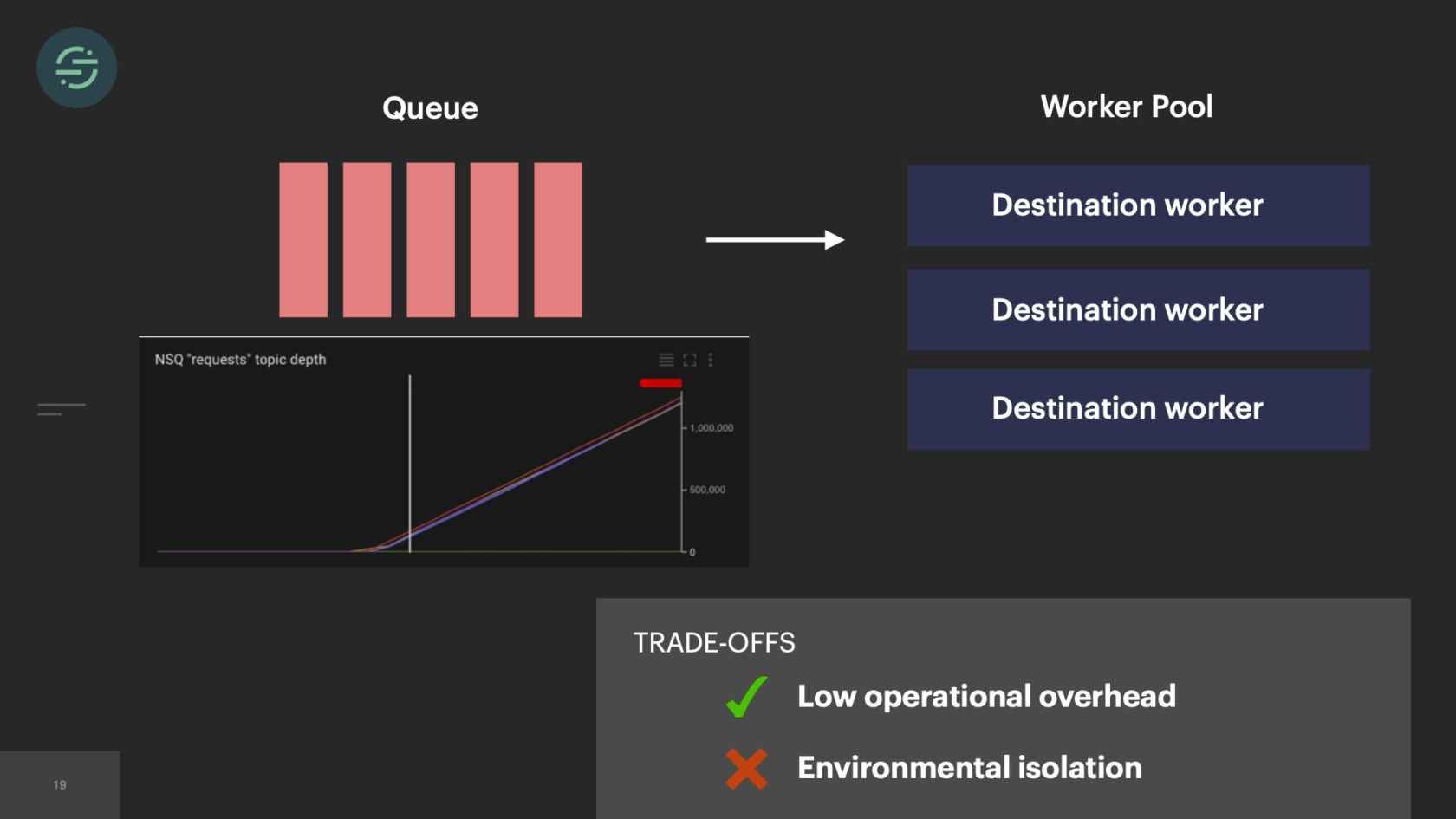
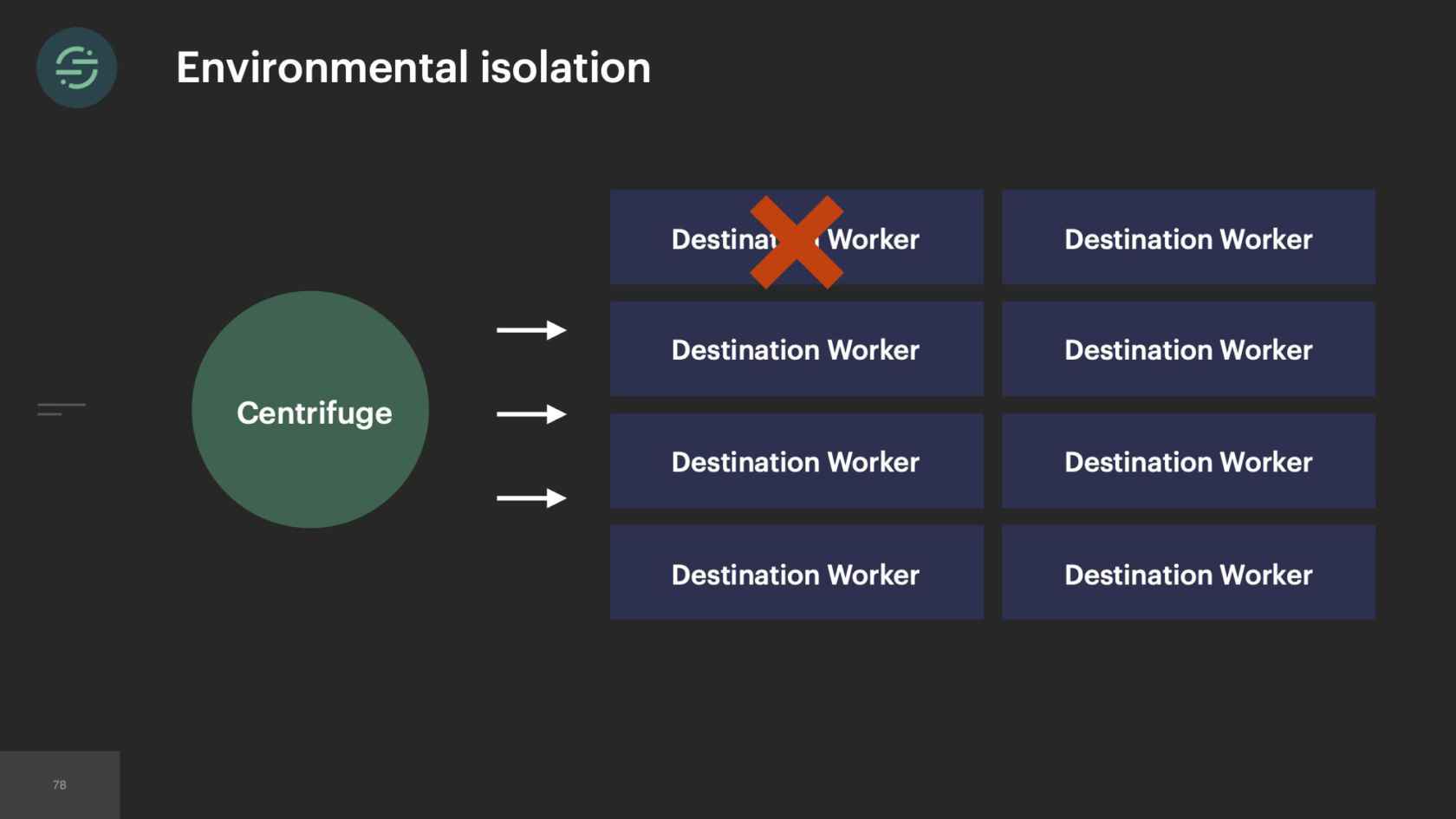
Now we're at a point we had this monolith in production for about a year and the operational overhead is great. This environmental isolation between the destinations is really starting to bite us. About 10% of requests that we send out to destinations fail with a retryable error. This is something that we were constantly dealing with. It was a huge point of frustration. A customer that would not even be using Salesforce would be impacted by a Salesforce outage. This trade-off is what inspired us to move to microservices.
The Switch to Microservices
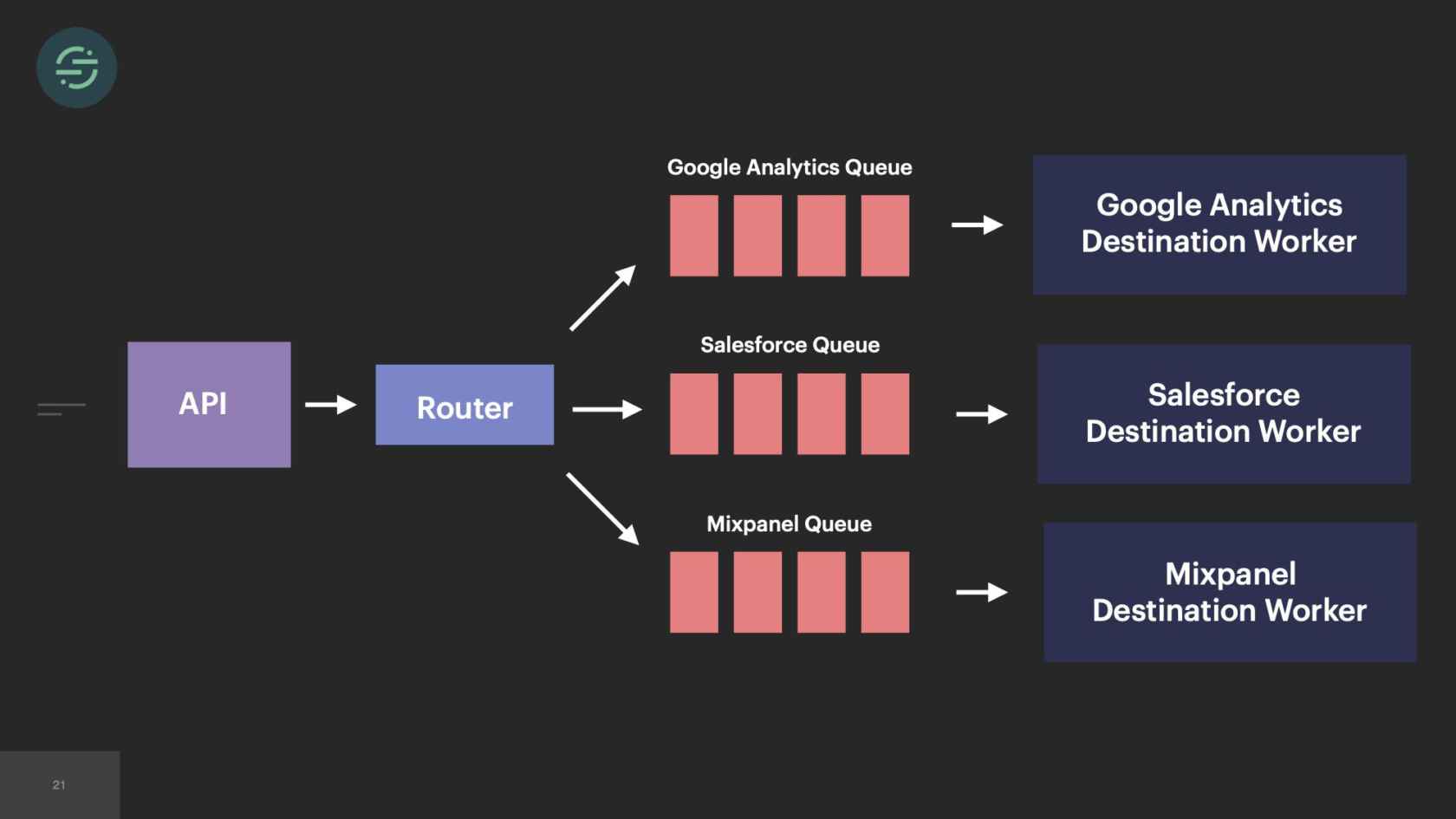
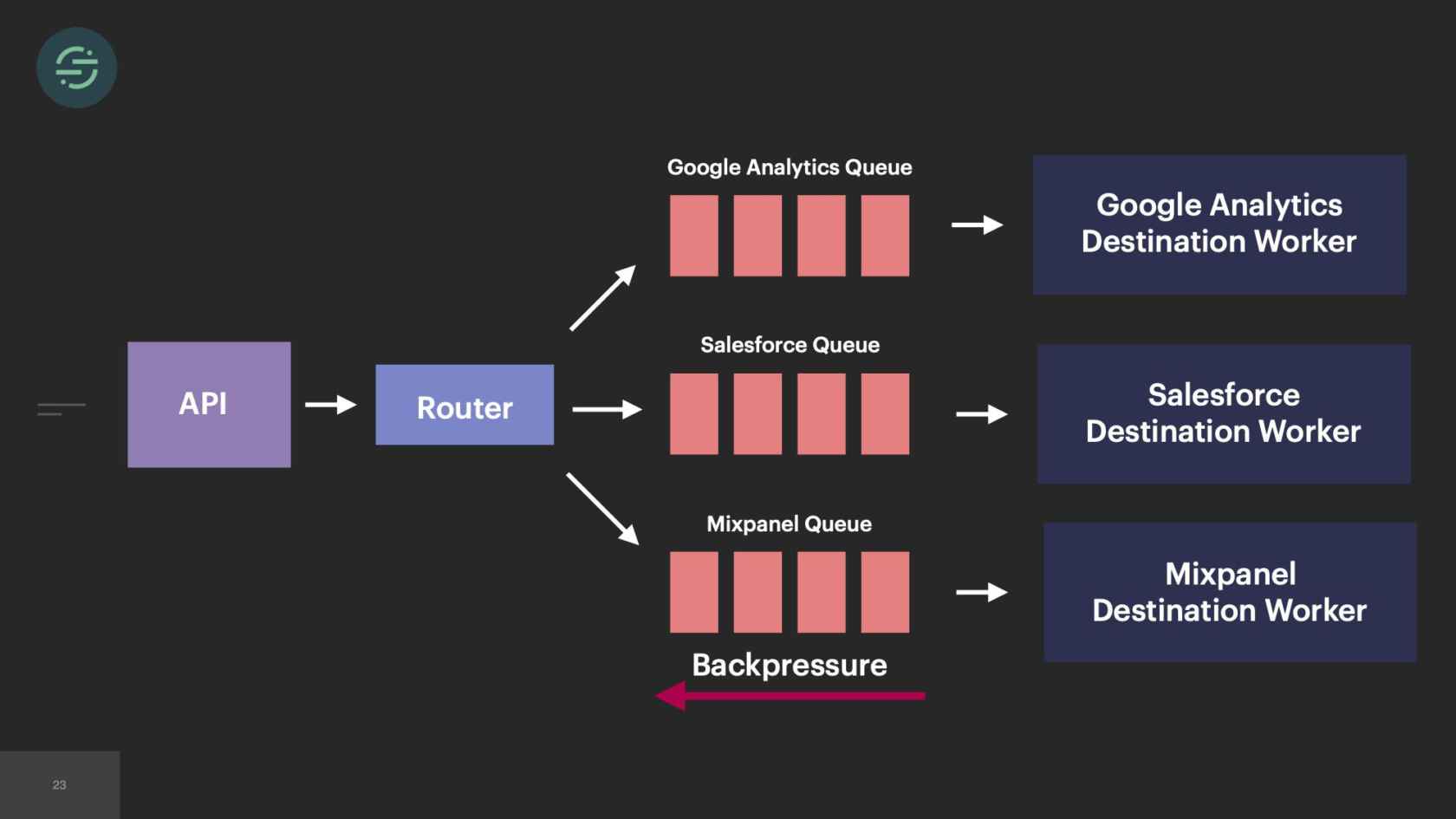
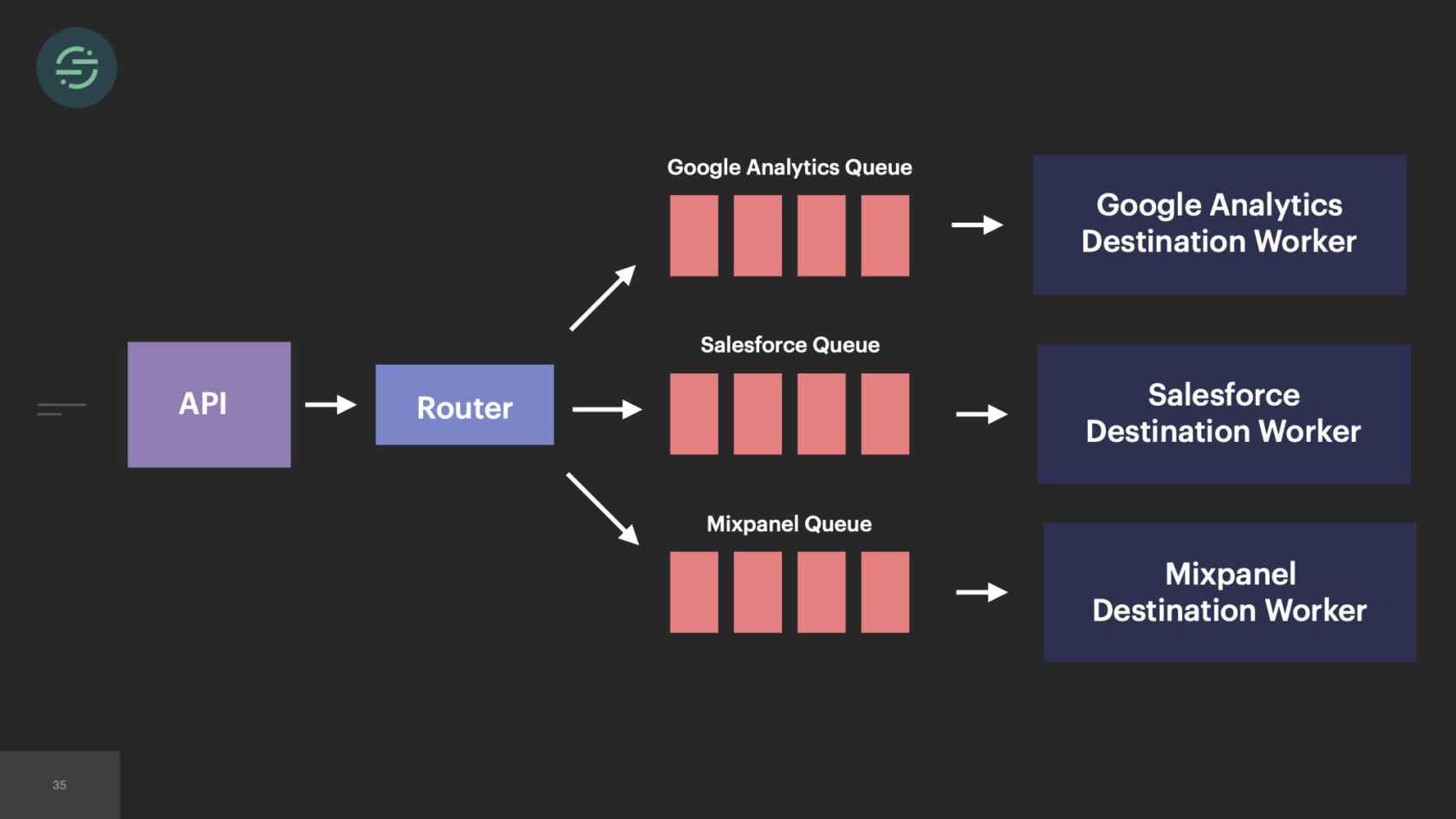
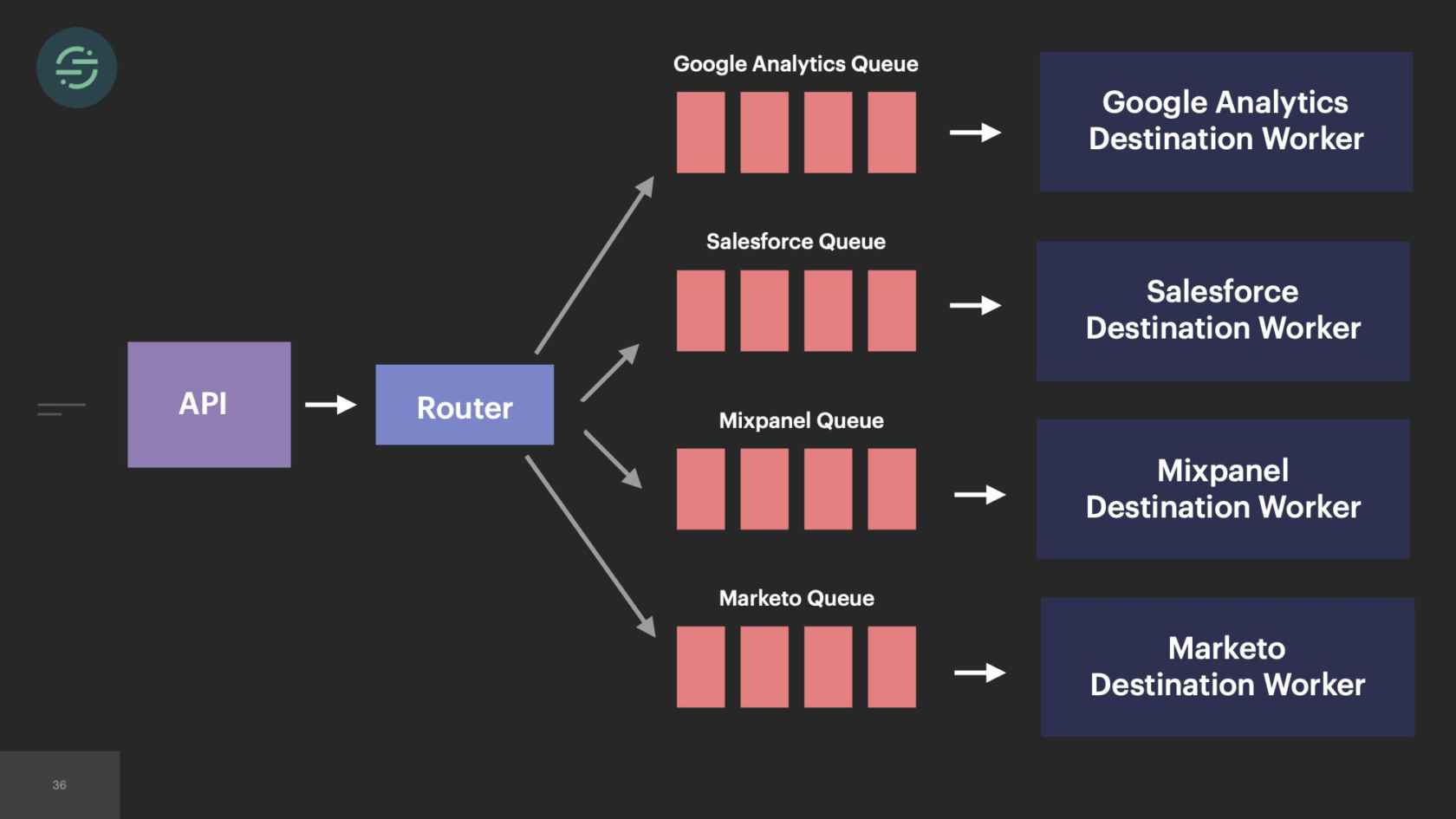
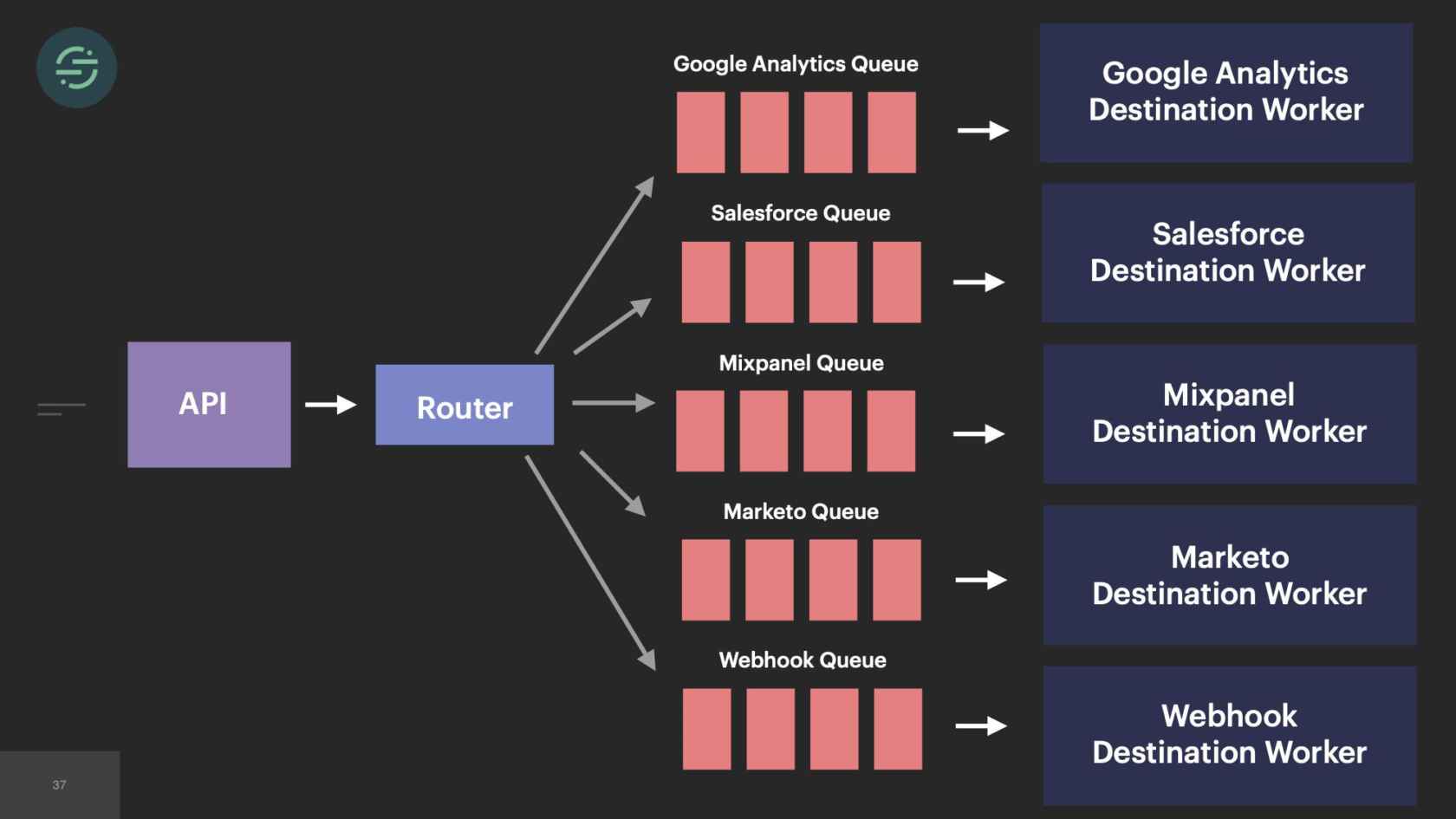
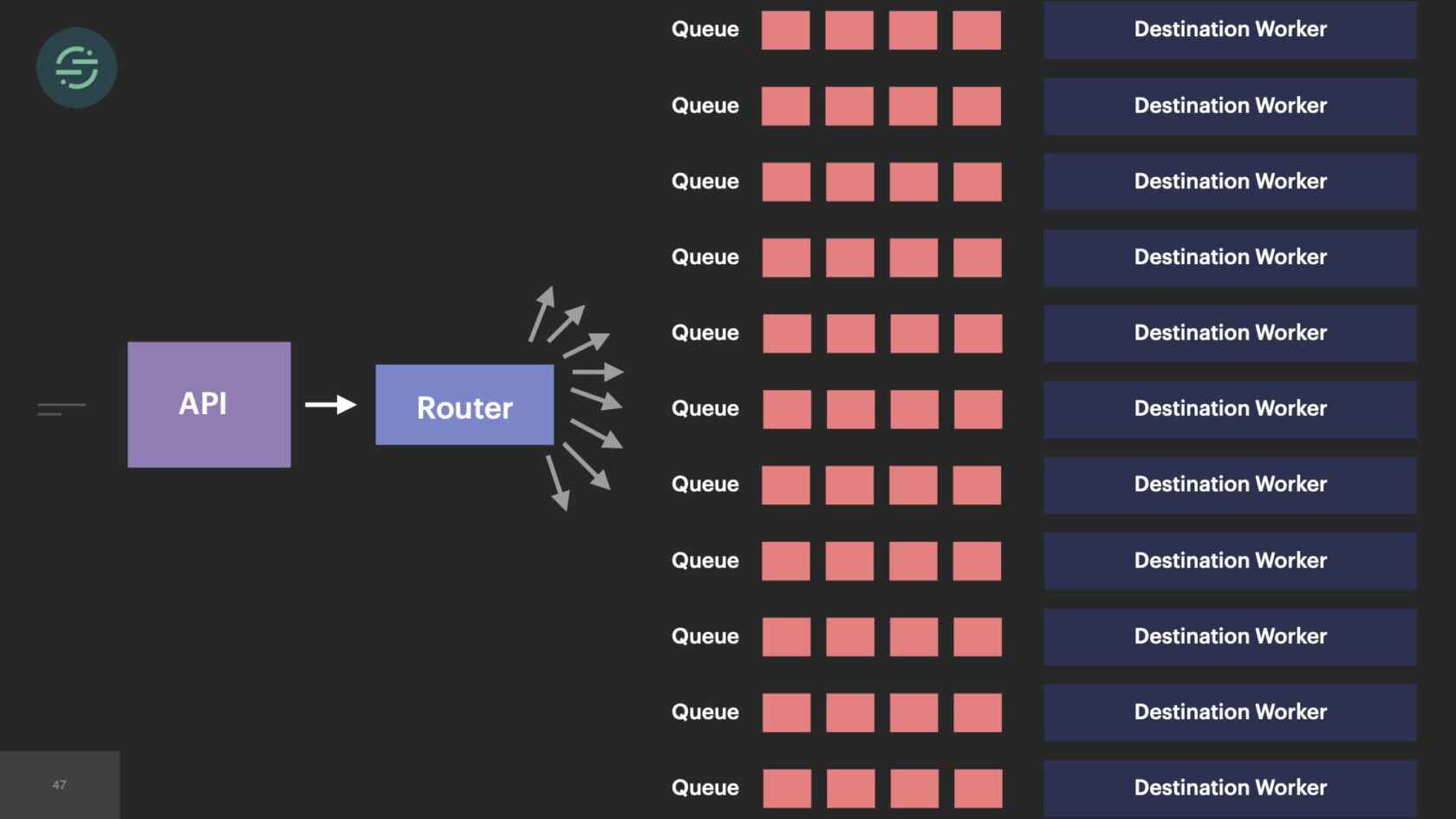
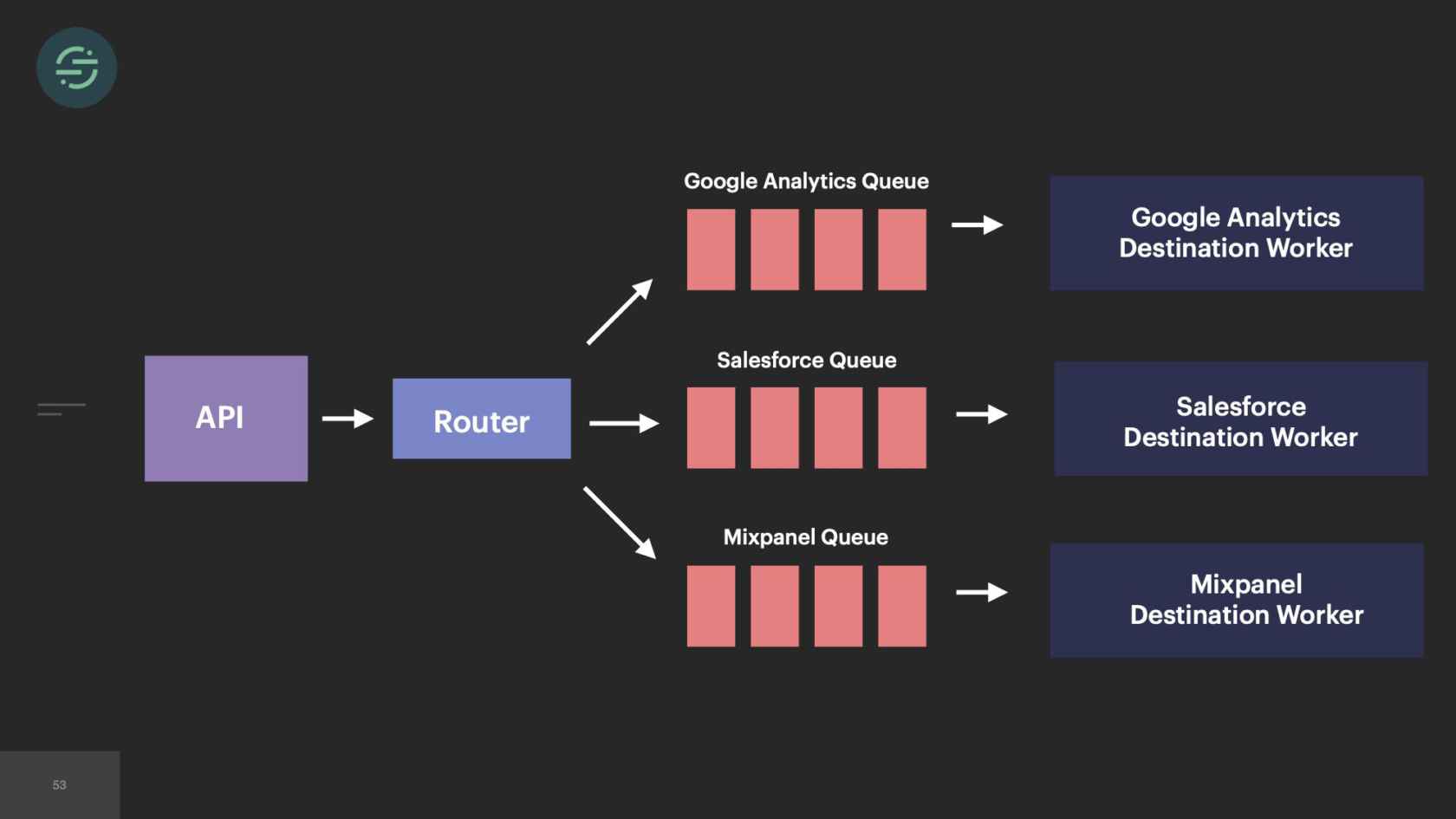
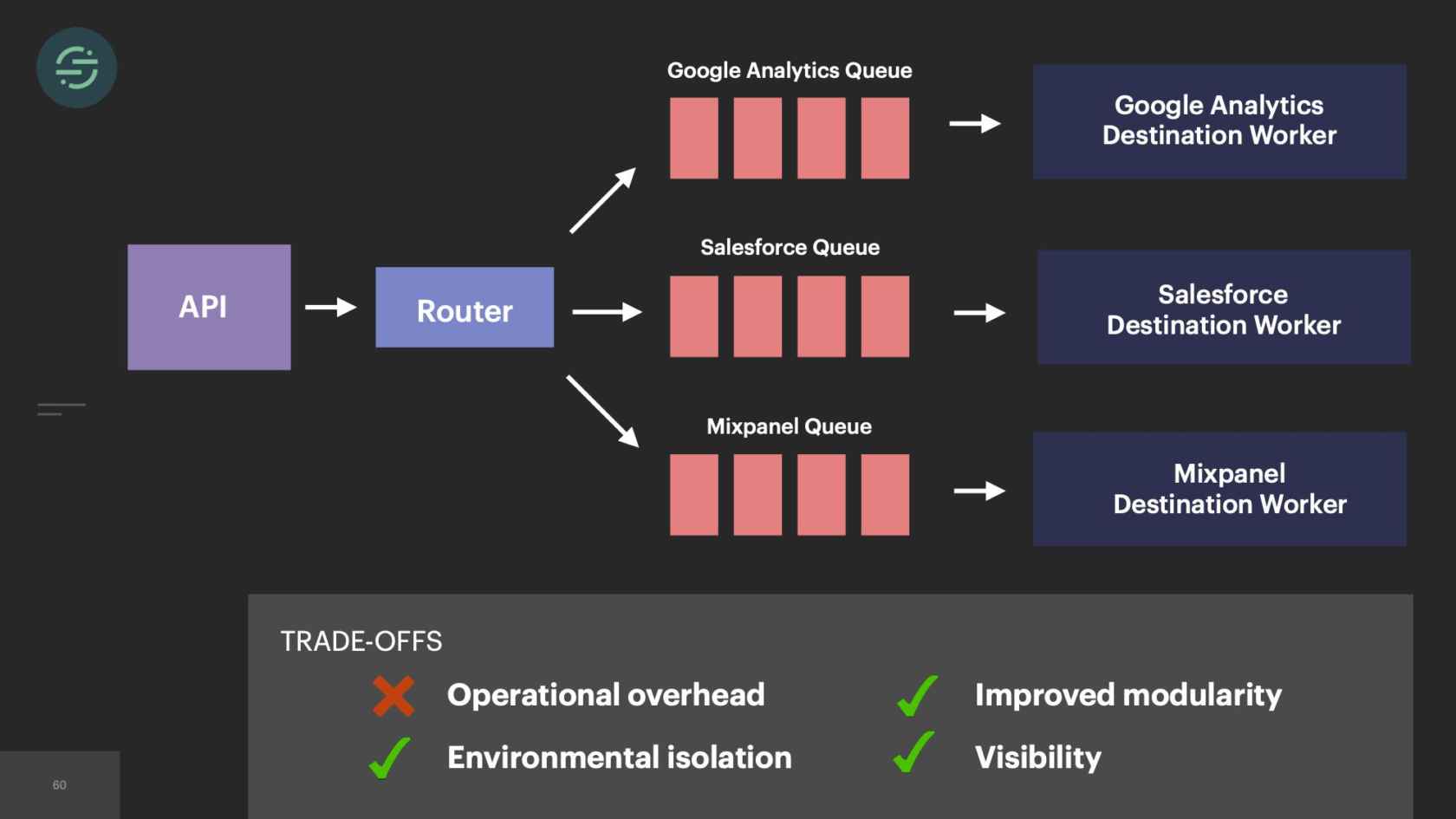
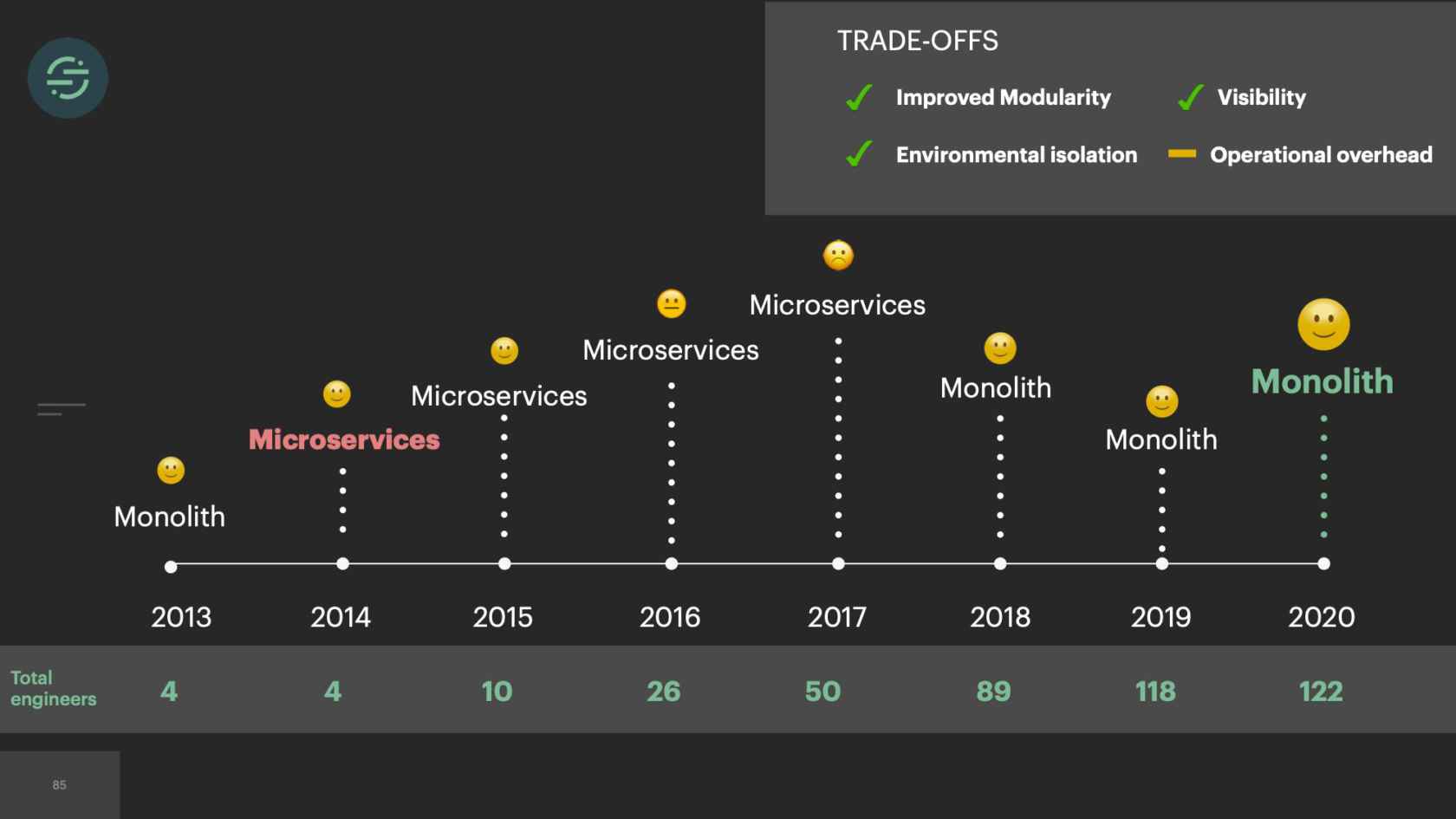
In 2014, we made the switch to microservices, because environmental isolation is something that comes naturally when you make the switch to microservices. This is what the new architecture looked like. Now we have the API that's ingesting events, and forwarding them to a router process. This router process is responsible for fetching customer managed settings to see which destination the event needs to go to. Then it makes a copy of the event and distributes it to each destination-specific queue. Then at the end of each queue, there's a destination specific worker that is responsible for handling messages.
Our microservice architecture allowed us to scale our platform like we needed to at the time for a few different reasons. The first was it was our attempt to solve that head-of-line blocking issue that we saw. If a destination was having issues, only its queue would back up and no other destinations would be impacted. It also allowed us to quickly add destinations to the platform. A common request that we would get is our sales team would come in, say, "We have this big, new customer, but they want to use Marketo. We don't support Marketo. Can you guys add that in?" We'll be like, "Sure." We'd add another queue, and another destination worker to support Marketo. Now I can go off and build this Marketo destination worker without worrying about any of the other destinations.
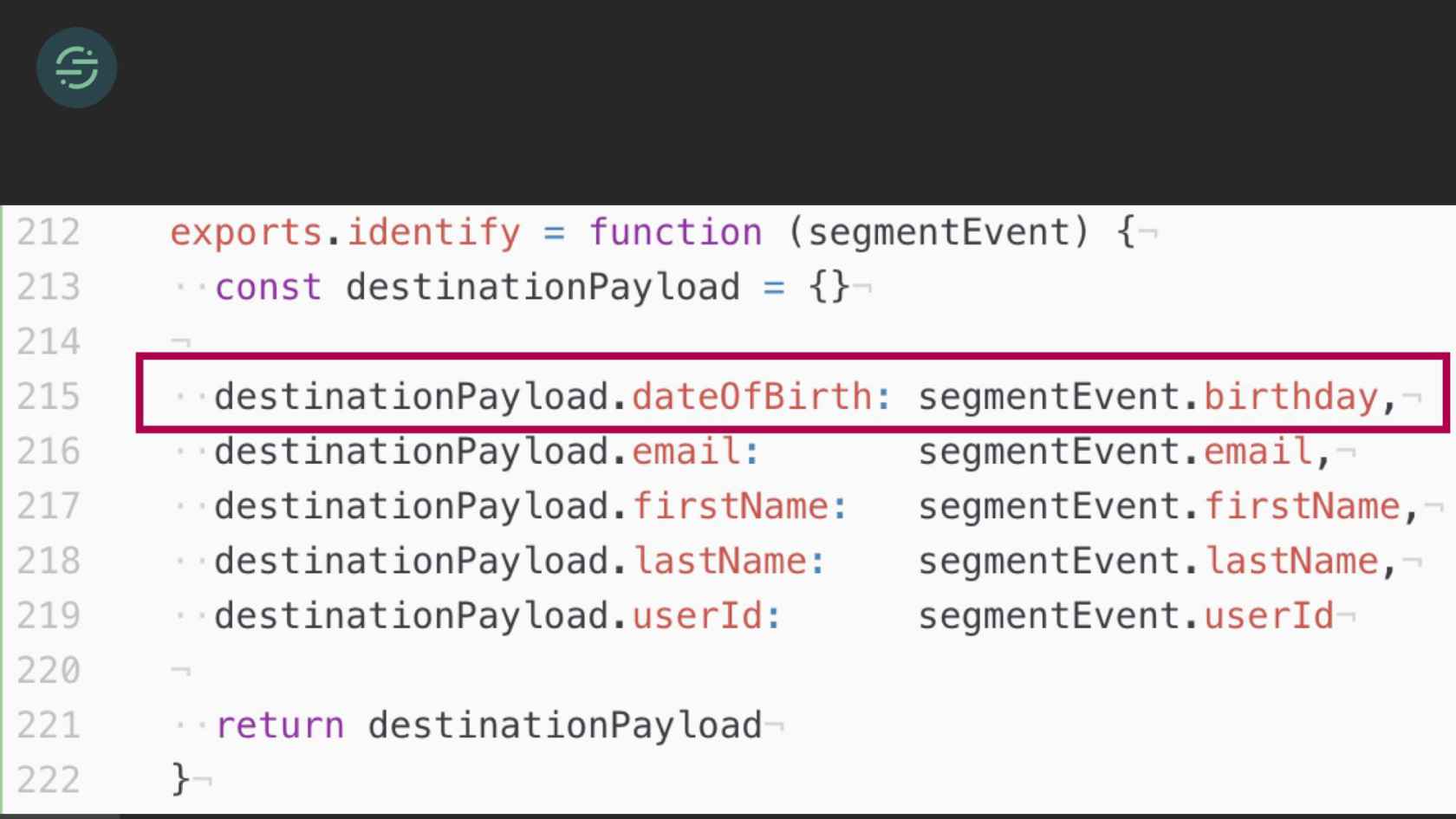
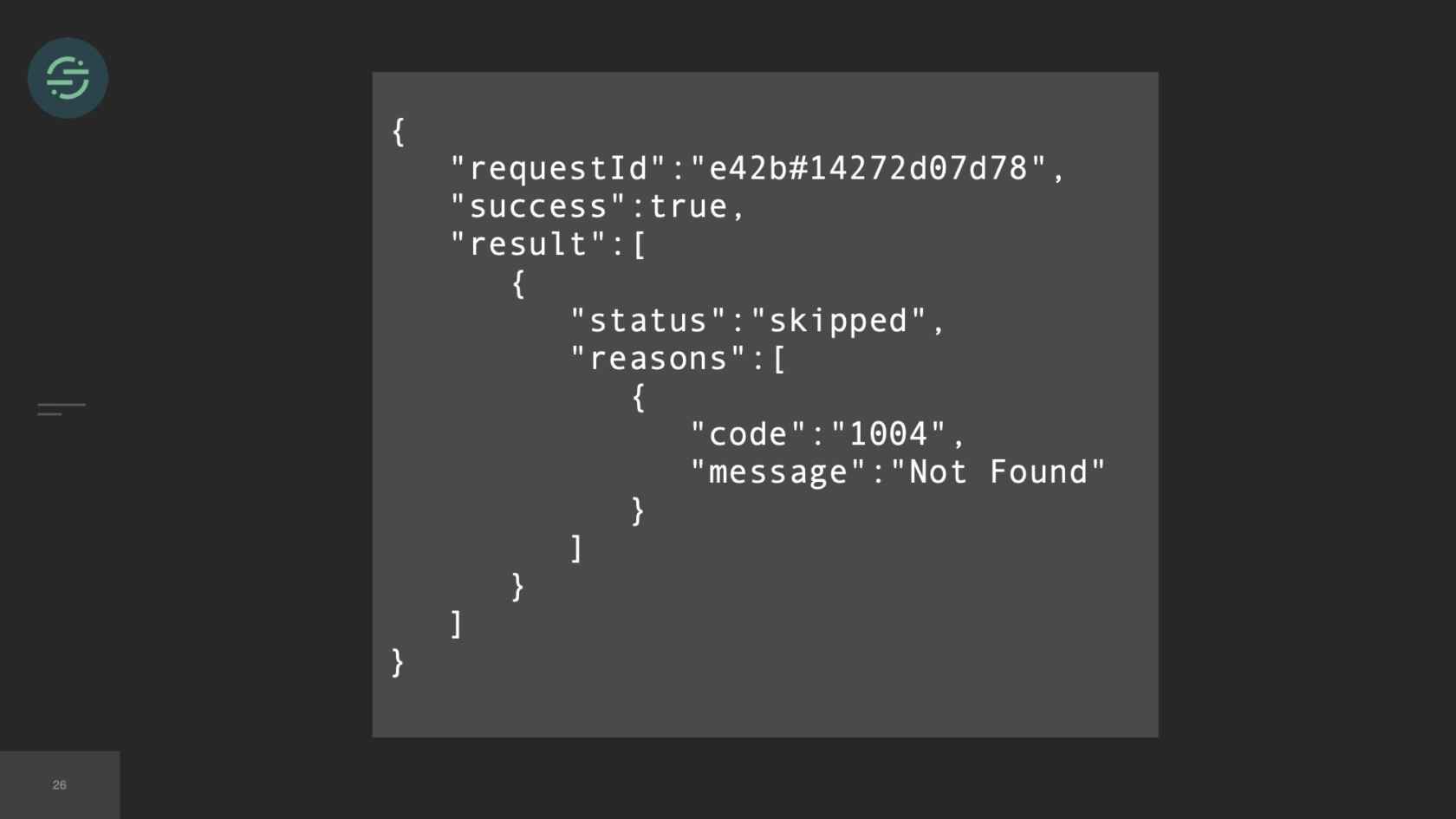
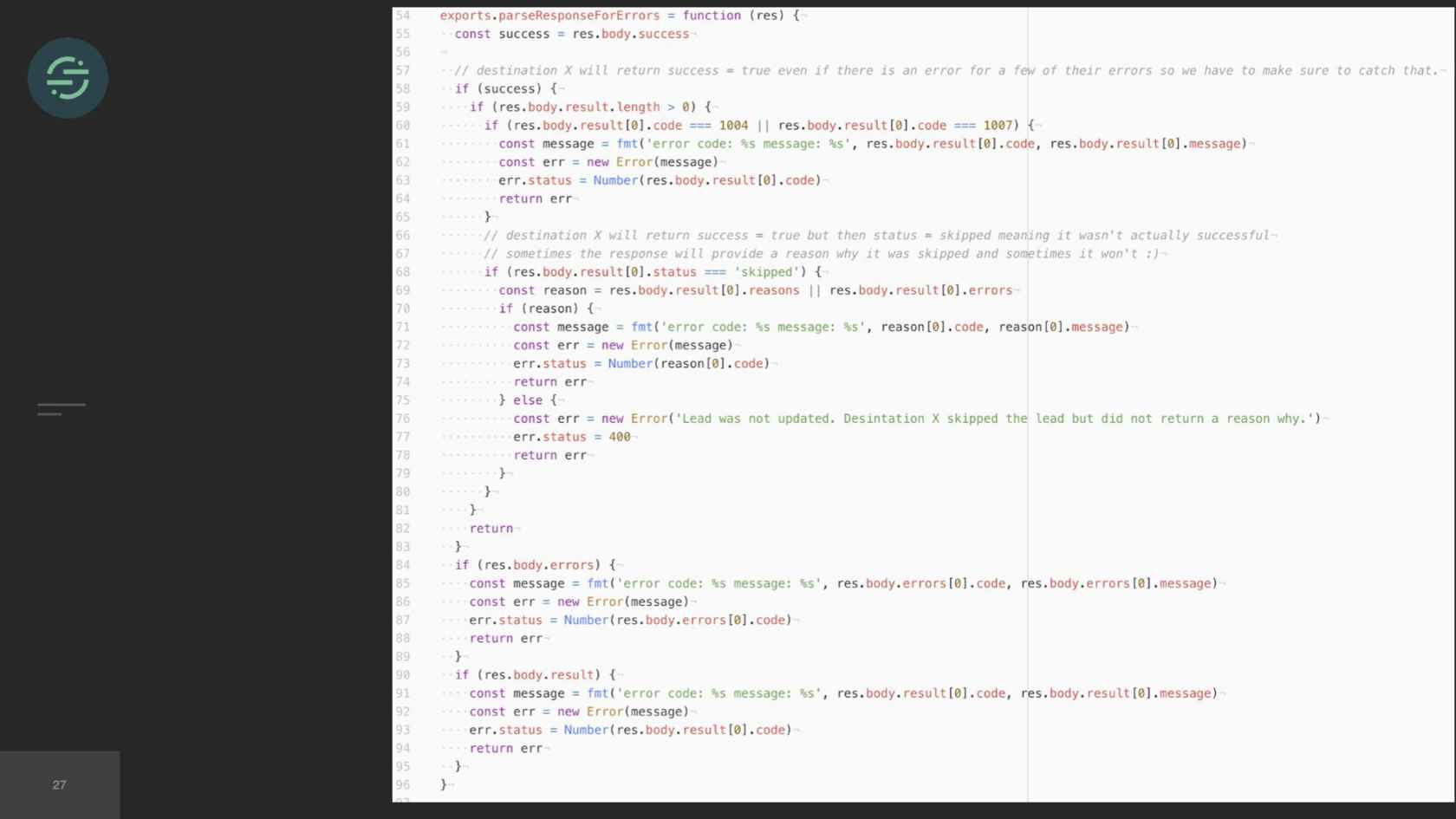
In this situation, the majority of my time is actually spent understanding how Marketo's API works and ironing out all the edge cases with their API. For example, each destination requires events to be in a specific format. For example, one destination would expect birthday as data of birth, our API accepts it as birthday. Here's an example of a relatively basic transform that the destination worker would be responsible for. Some of them are pretty simple like this one, but some of them can be really complex. One of our destinations, for example, requires payloads to be in XML. Another thing that the worker is responsible for is not every destination sends responses back that are in a standard HTTP format. For example, this is one of our destinations, and it returns a 200. If you look, you'll see it says success true. Then if you look at the results array, it was actually a not found error. This is the code that we have to write for this destination now, to parse every single response we're getting back from that destination to understand if we need to retry the error or not.
Mono-repo vs. Micro-repo
When you move to microservices, something that comes up often is, do you keep everything in a mono-repo, or do you break it out into micro-repos and have one repo per service? When we first broke out everything into microservices, we actually kept everything in one repo. The destinations were broken out into their subdirectories. In these subdirectories lived all the custom code that we just went over for each destination, as well as any unit test that they had to verify this custom code.
Something that was causing a lot of frustration with the team was if I had to go in and make a change to Salesforce. Marketo's tests were breaking. I'd have to spend time fixing the Marketo test to get out my change for Salesforce. In response to that, we broke out all the destinations into their own repos. This isolation allowed us to move quickly when maintaining destinations, but we'll find out that this turned out to be a false advantage and came back to bite us.
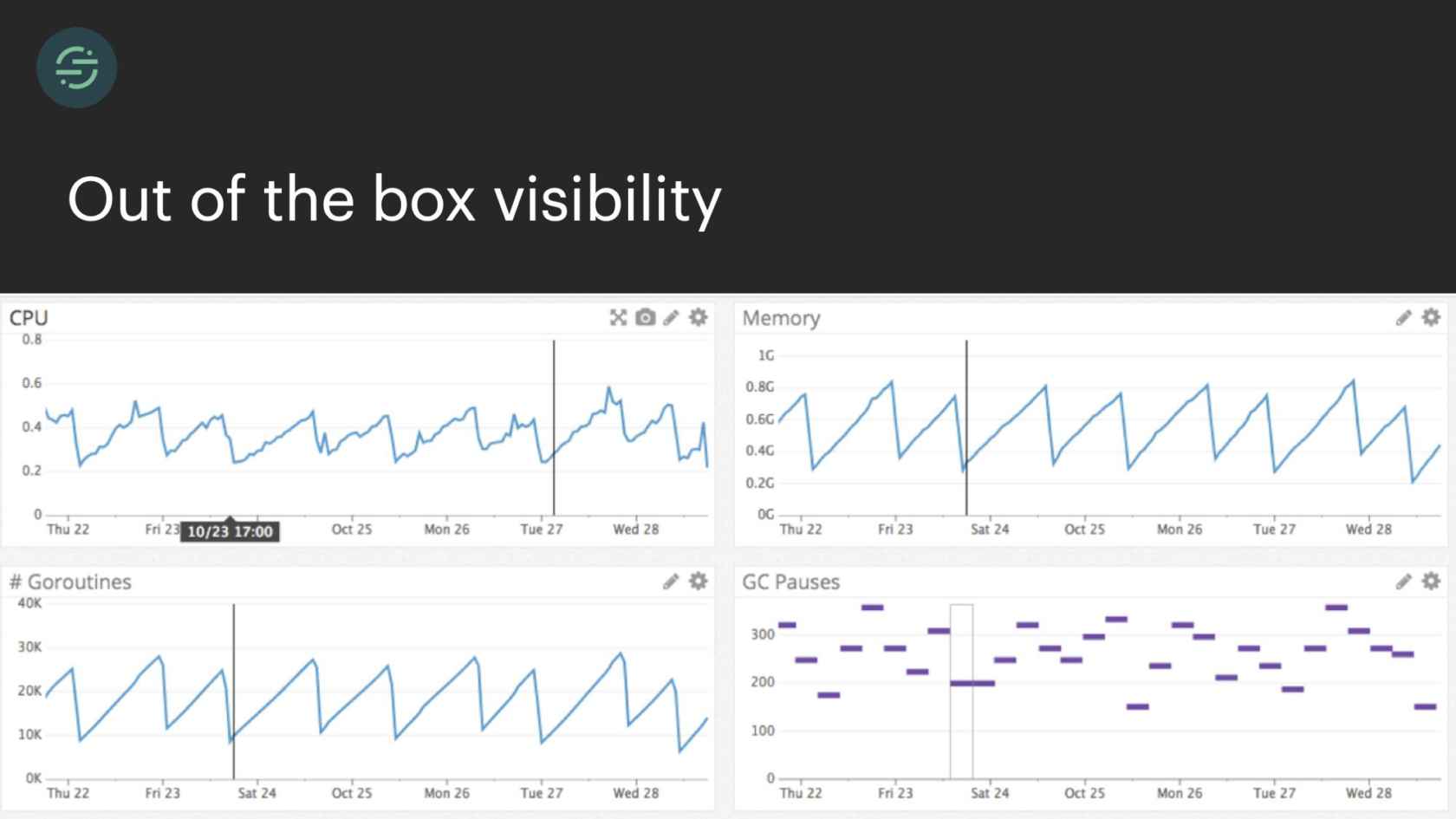
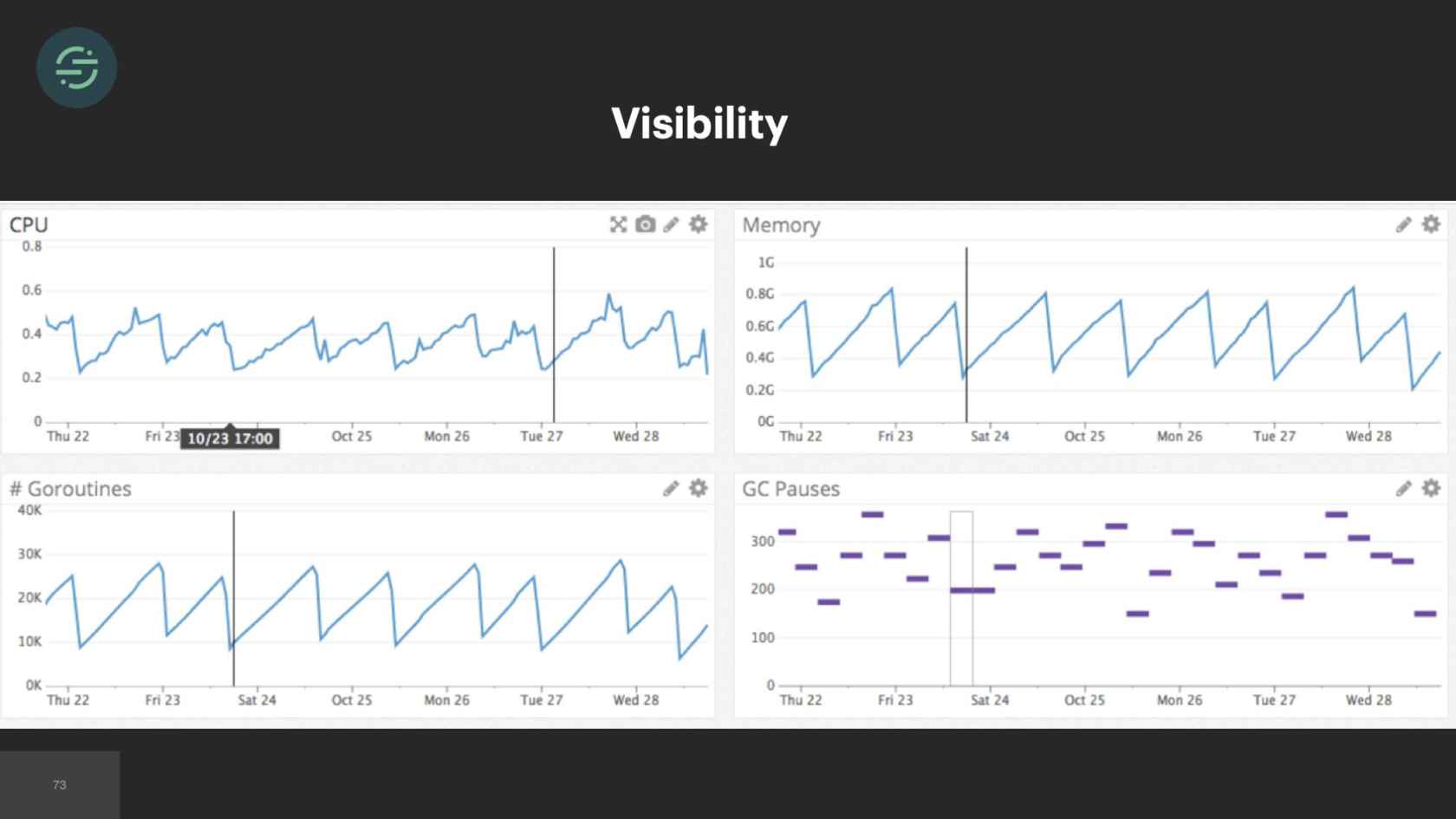
The next and final benefit that we got from microservices, which is a little specific to Segment is we got really good visibility out of the box into our infrastructure. Specifically, the visibility that I'm talking about is program execution, like hot code paths and stack size. Most tools aggregated these types of metrics on the host, or the service level. You can see here, we had a memory leak. With all the destinations separated out, we knew exactly which destination was responsible for it.
Something we were constantly paged for was queue depth. Queue depth is generally a good indicator that something is wrong. With our one-to-one destination worker queue setup, we knew exactly which destination was having issues. The on-call engineer can then go check the logs for that service and understand relatively quickly what was happening. You definitely can get this type of visibility from a monolith. You don't get it for free right away. It takes a bit of time and effort to implement.
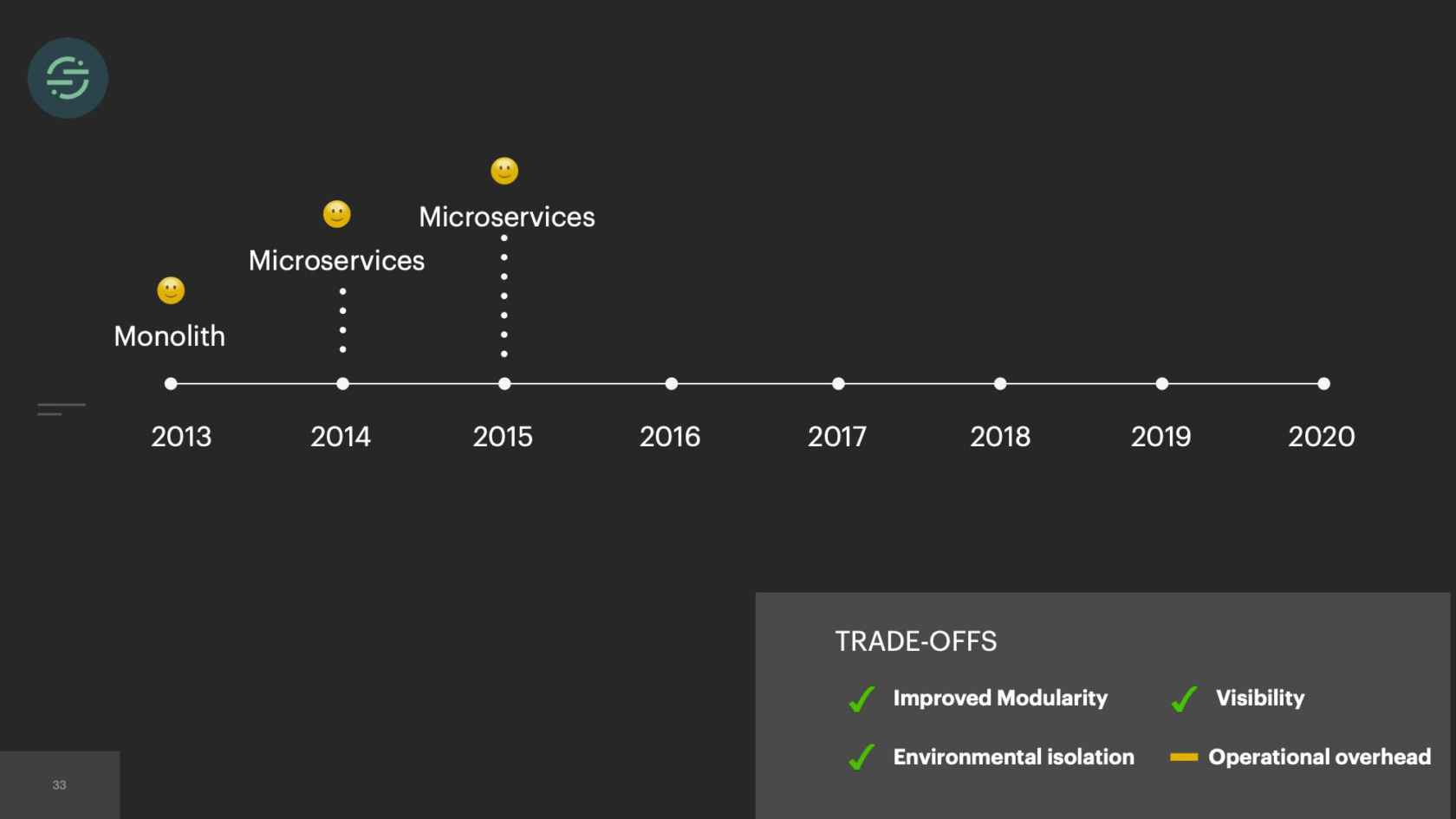
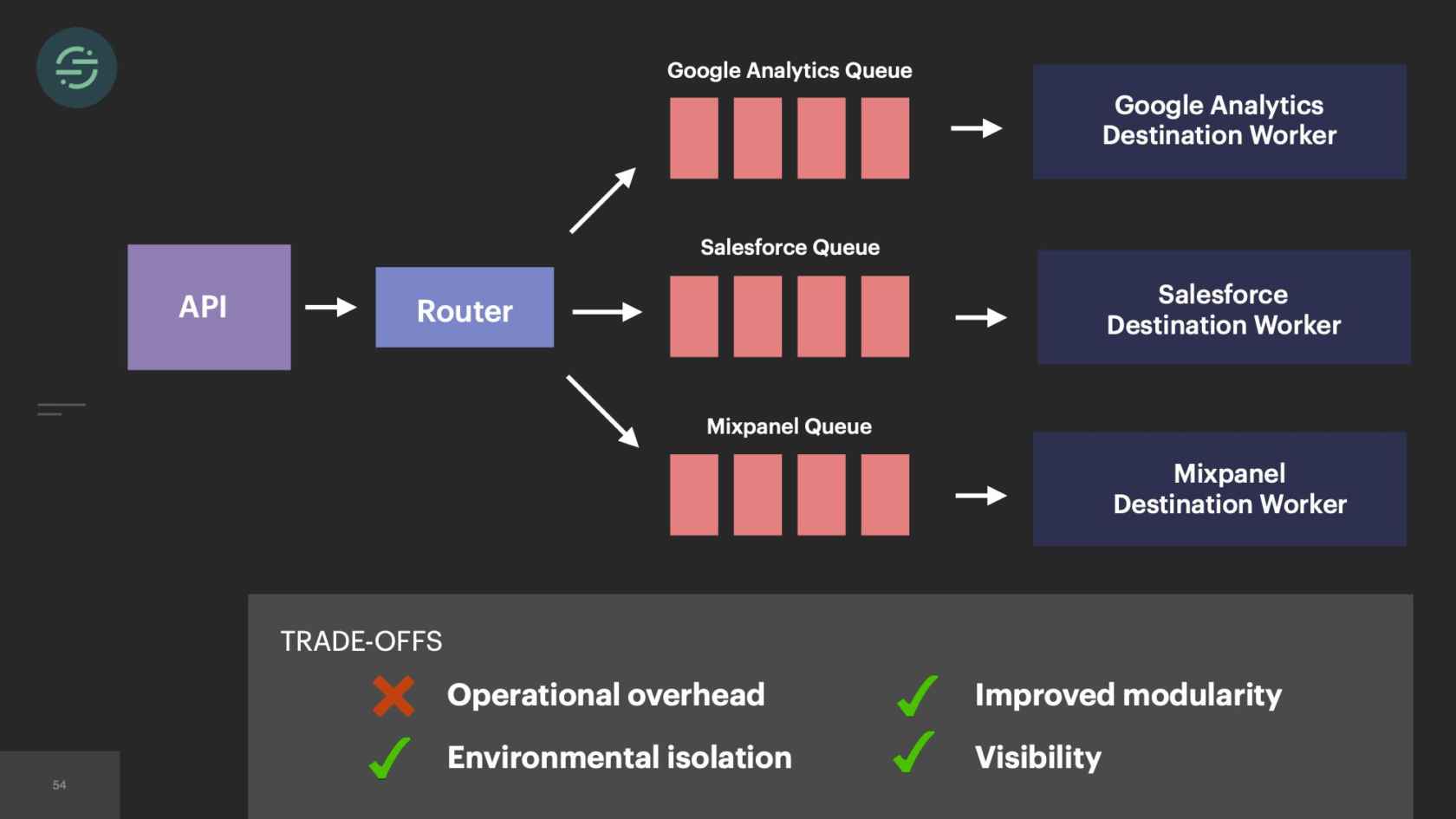
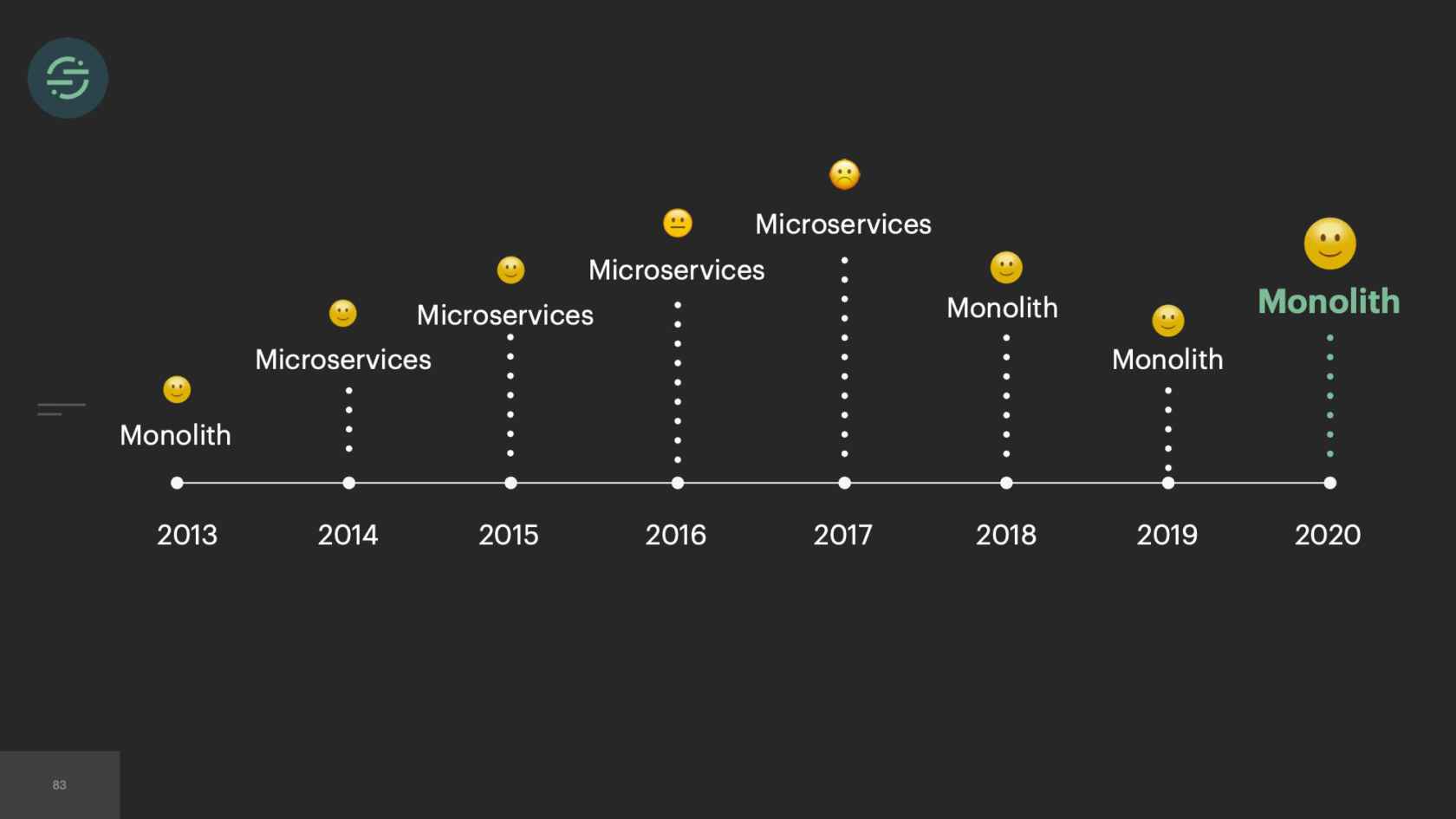
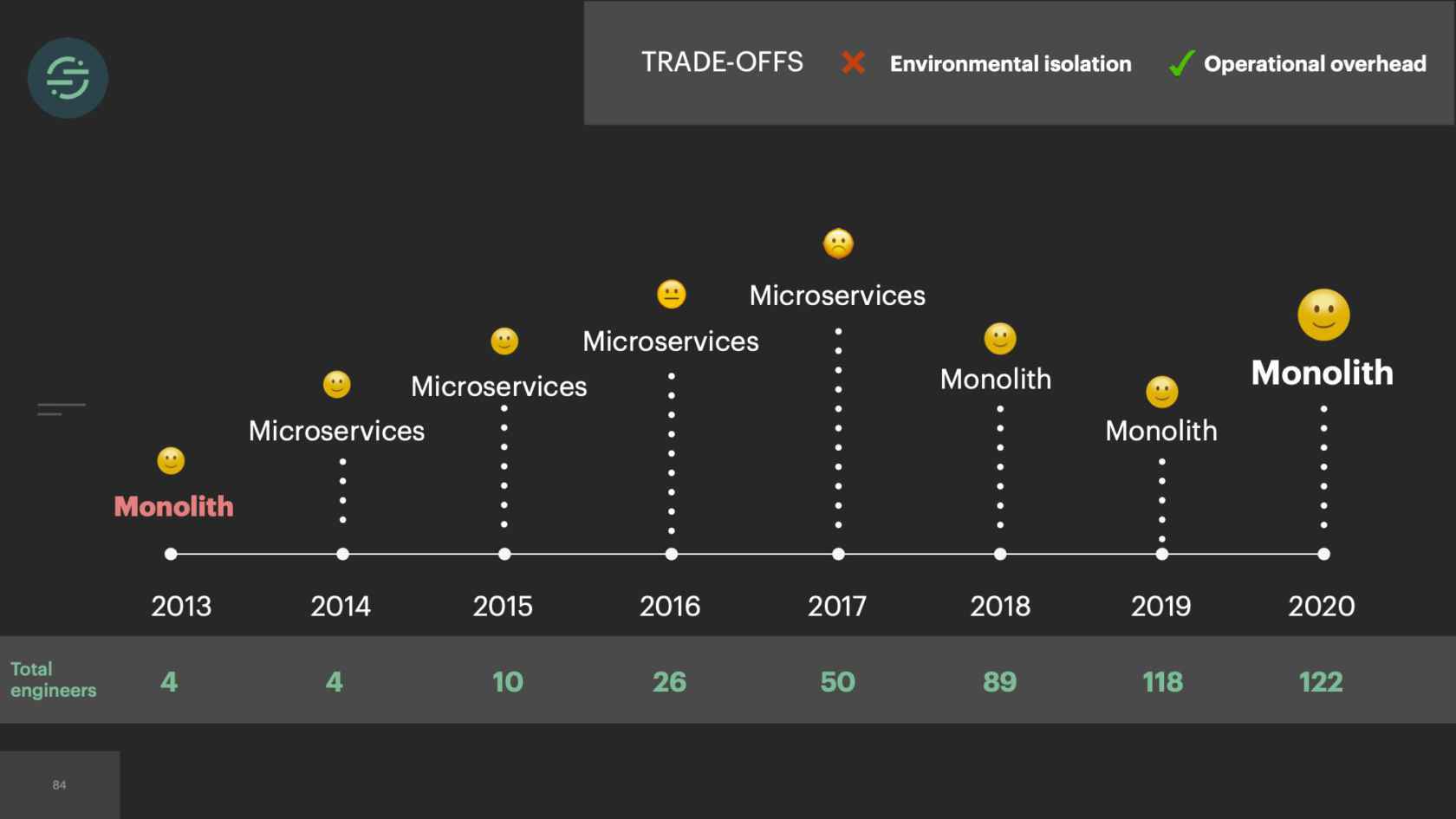
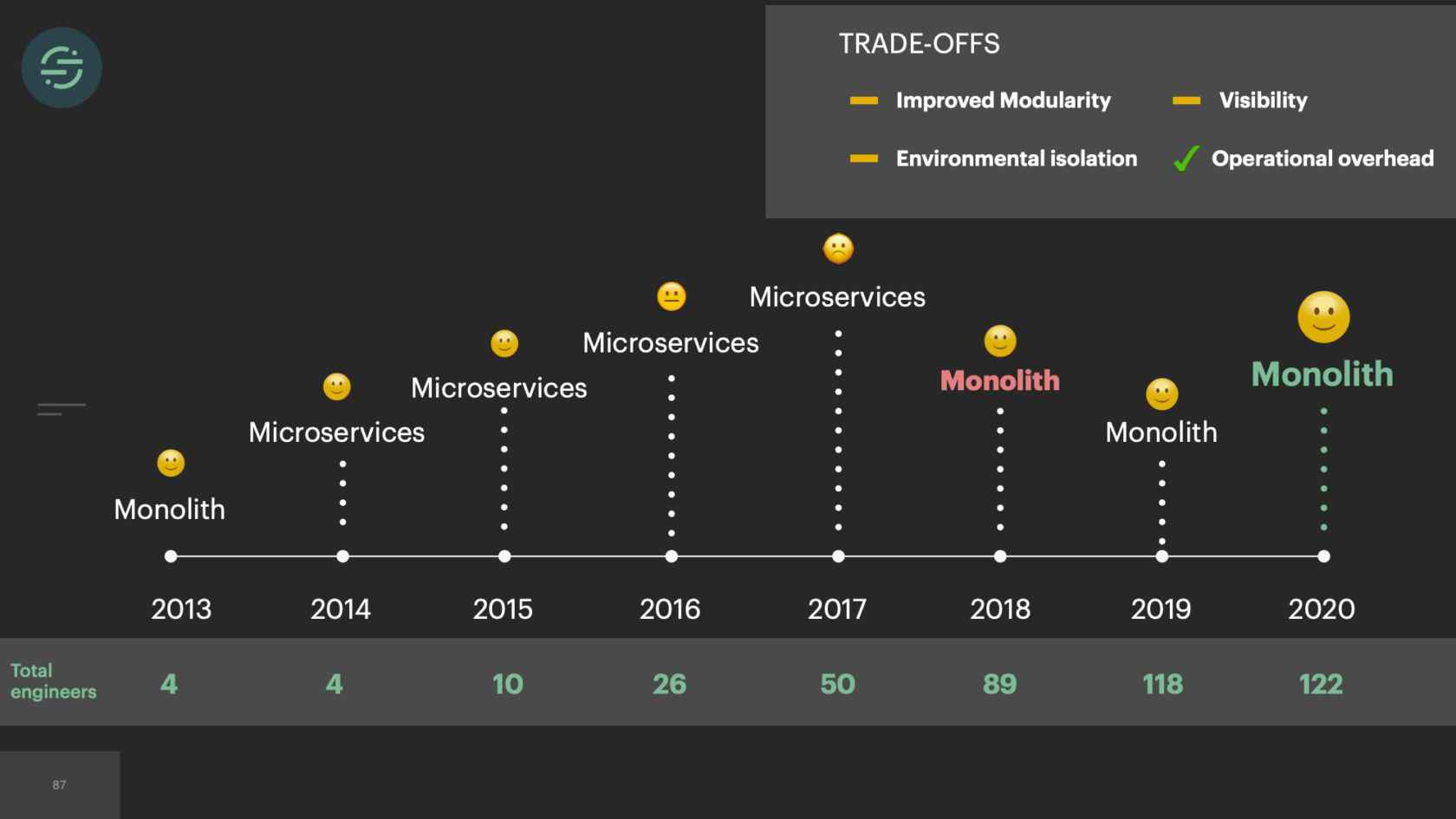
2015, we only had about 10 engineers total. Our microservice setup is allowing us to scale our product like we needed to at the time. If we look at the trade-offs, this is what we see. We have really good environmental isolation. Now one destination having issues doesn't impact anybody else. We have good, improved modularity. With all the destinations broken out into their own repos, failing tests don't impact any of the other destinations. We had this good default visibility. The metrics and logging that come out of the box with microservices significantly cut down on our time having to spend debug whenever we got paged. The operation overhead story isn't great, but it's not a real problem for us yet, because we only have about 20 destinations at this time. However, with the way our microservices are set up, this specific trade-off will soon be our downfall.
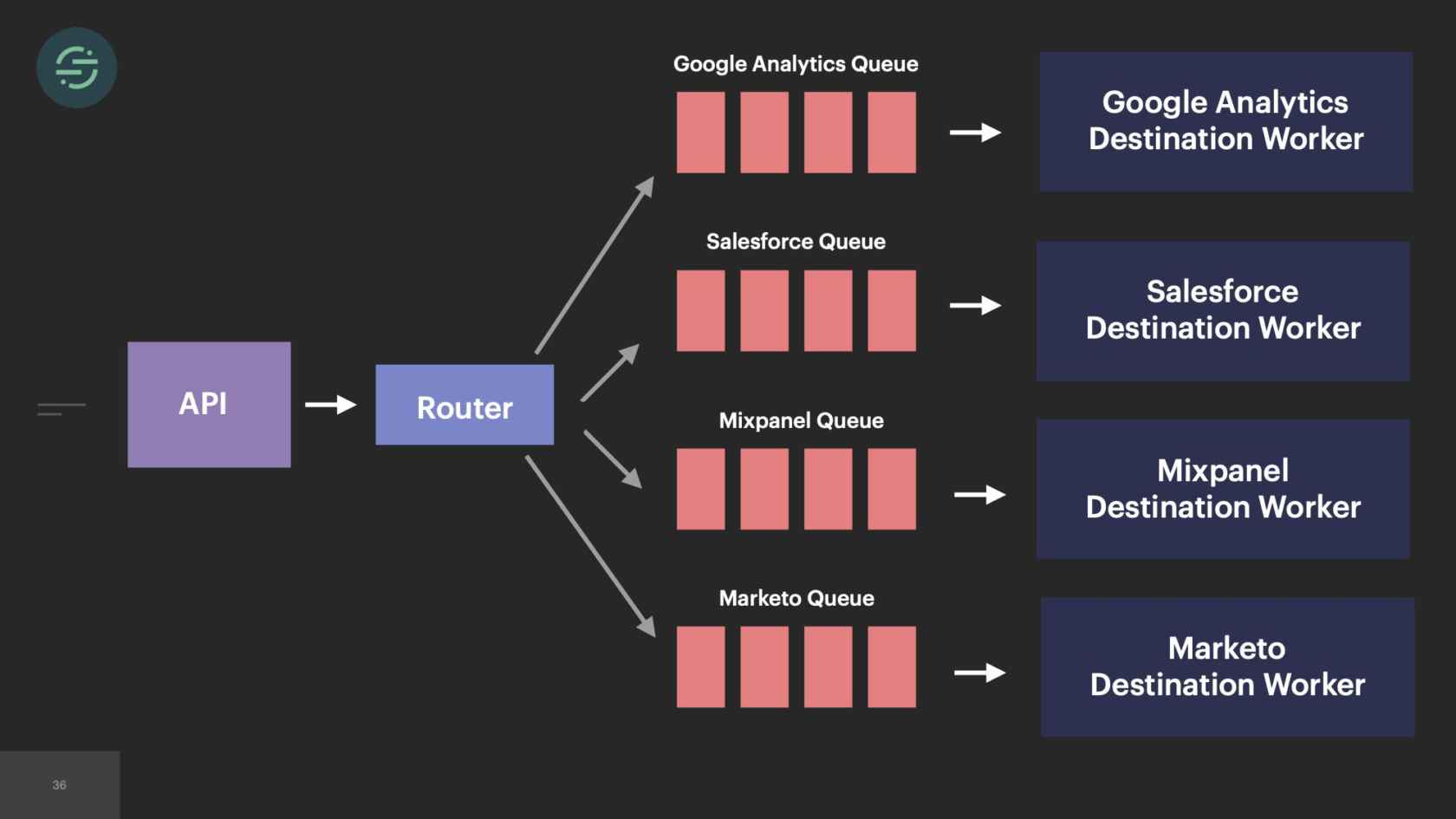
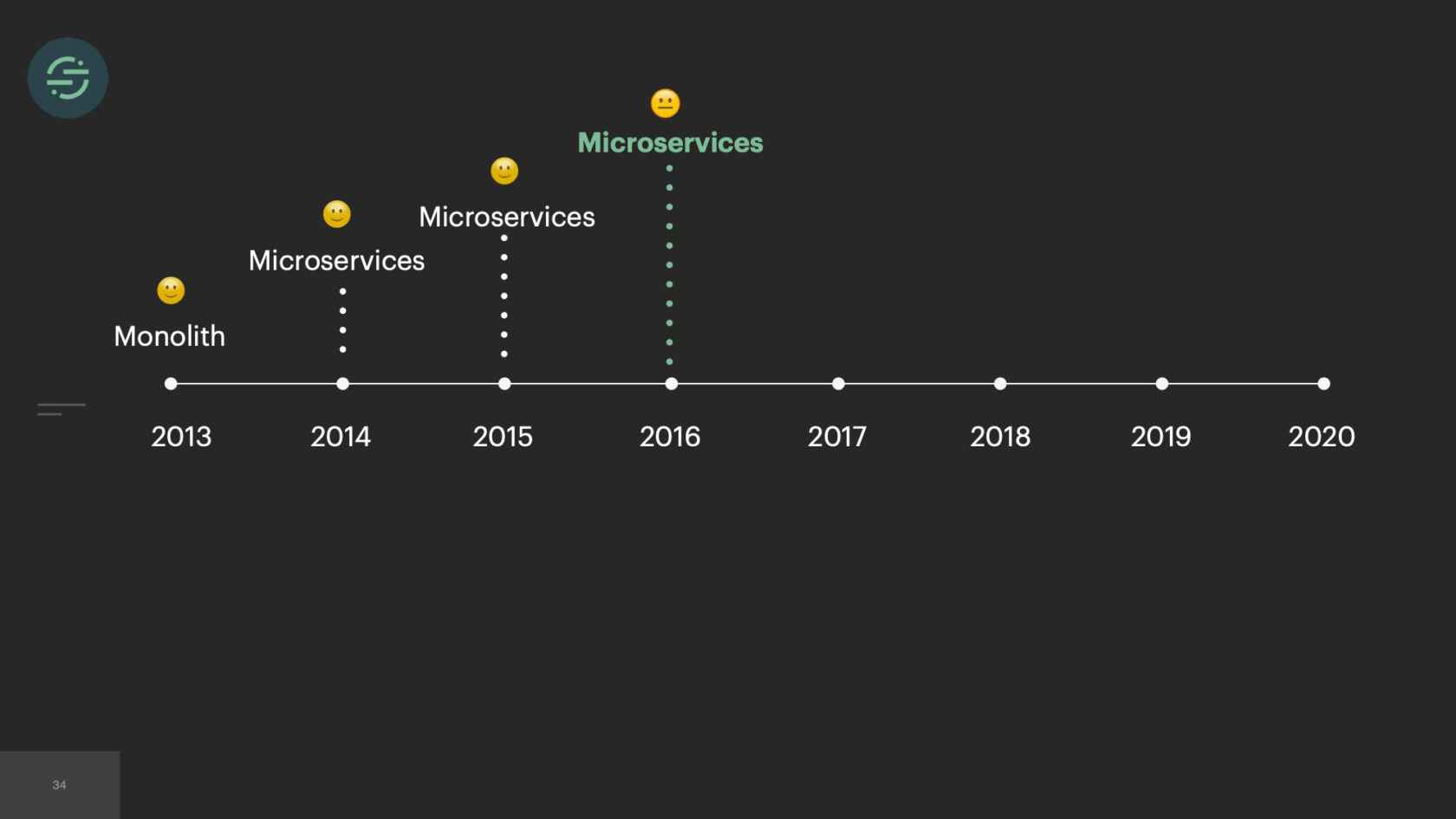
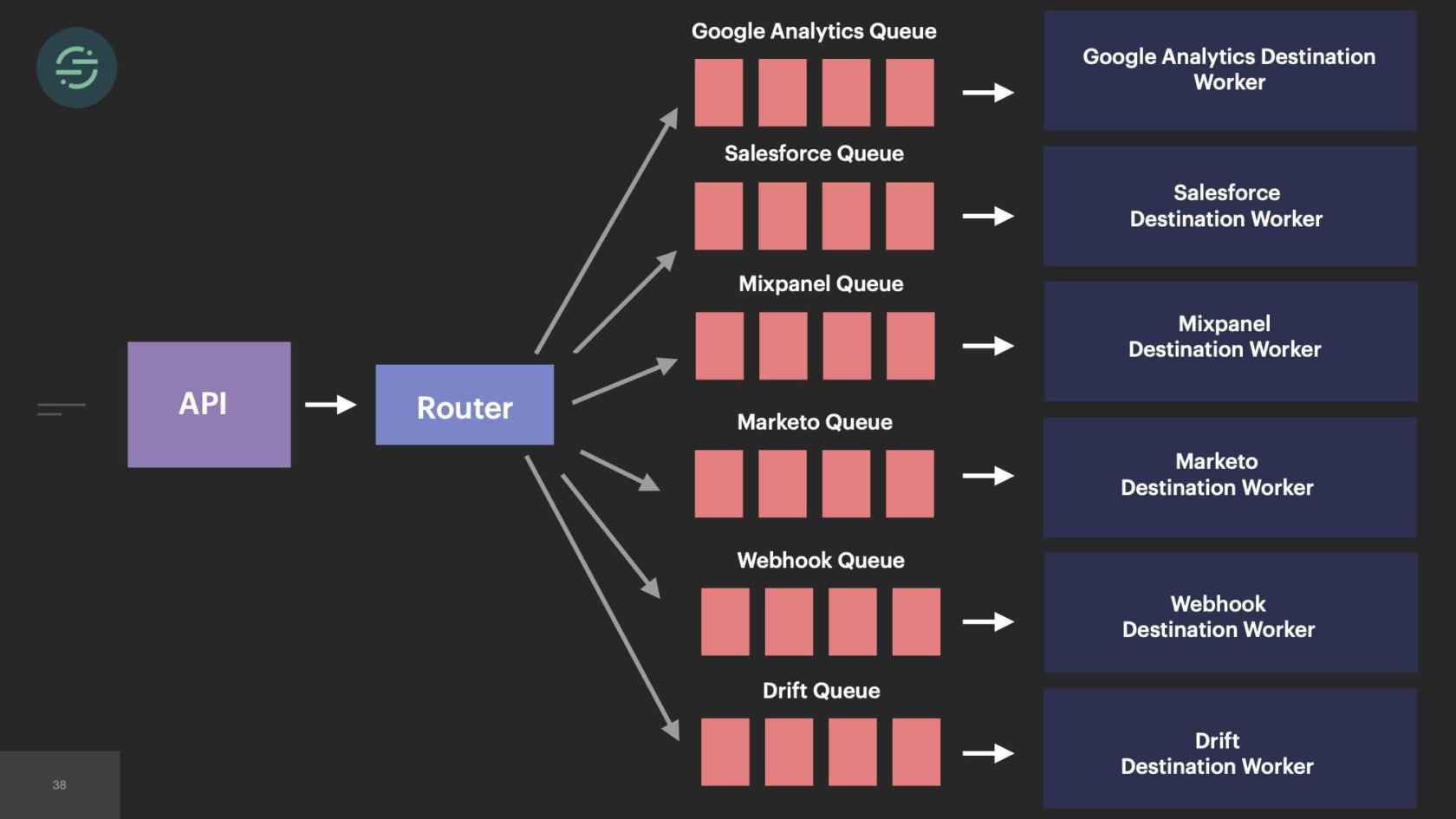
Now we're going to go into 2016. Our product is starting to gain some real traction. We're entering that hyper-growth startup phase. Requests with the sales team were happening more. They would come in, "We had this other new customer that's an even bigger deal. They want webhooks and we don't support webhooks. Can you add that in?" Of course, why not? Spin up a new queue, new destination worker. Another thing we were seeing was we're at the point where destinations were actually reaching out to us to be supported on our platform, which was really cool. In our microservice architecture, it was really easy to spin them up a new queue and a new worker. This keeps happening again over time.
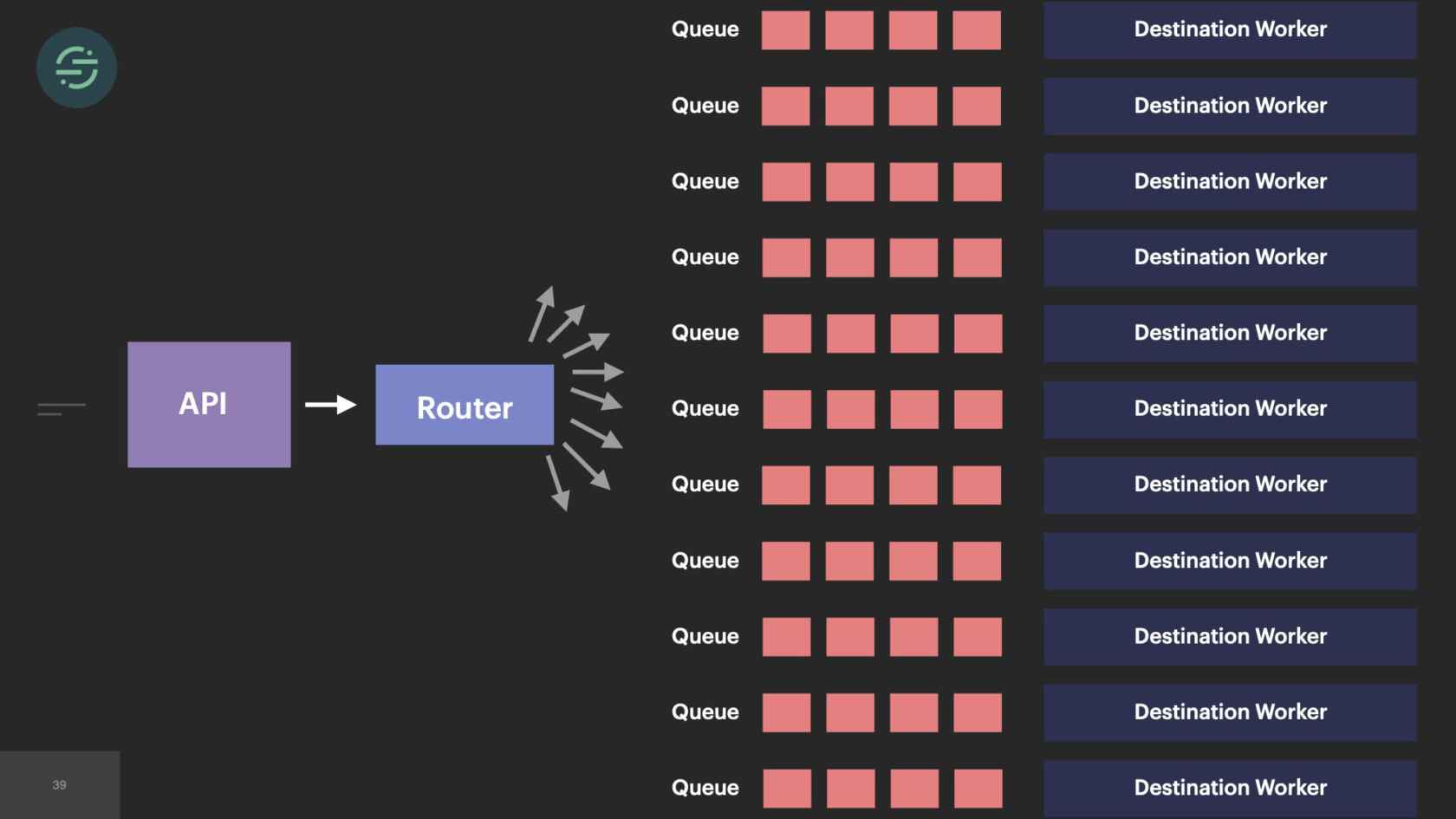
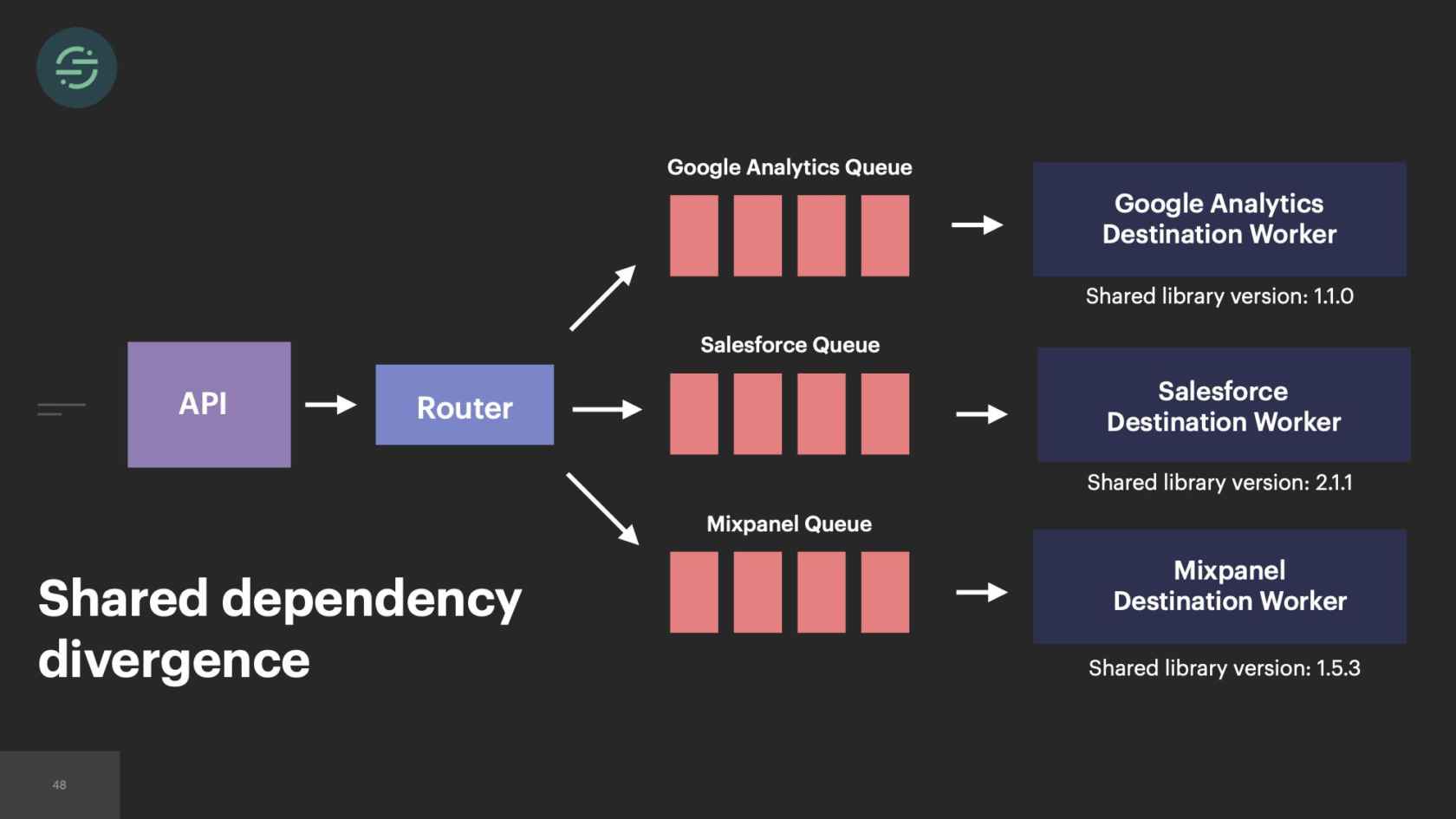
In 2017, we've now added over 50 new destinations. I couldn't quite fit 50 on here, but you get the idea. The thing is, though, with 50 new destinations, that meant 50 new repos. Each destination worker is responsible for transforming events to be compatible with the destination API. Our API will accept name in any of these formats. Either just name or first and last name, camelCase, first and last name, snake_cased. I want to get the name from this event. I have to check each of these cases in that destination code base. I'm already having to do a decent amount of context switching to understand the differences in destination APIs. Now all of our destination code bases also have specific code to get the name from Segment event. This made maintenance for us a bit of a headache. We wanted to decrease that customization across our repos as much as possible.
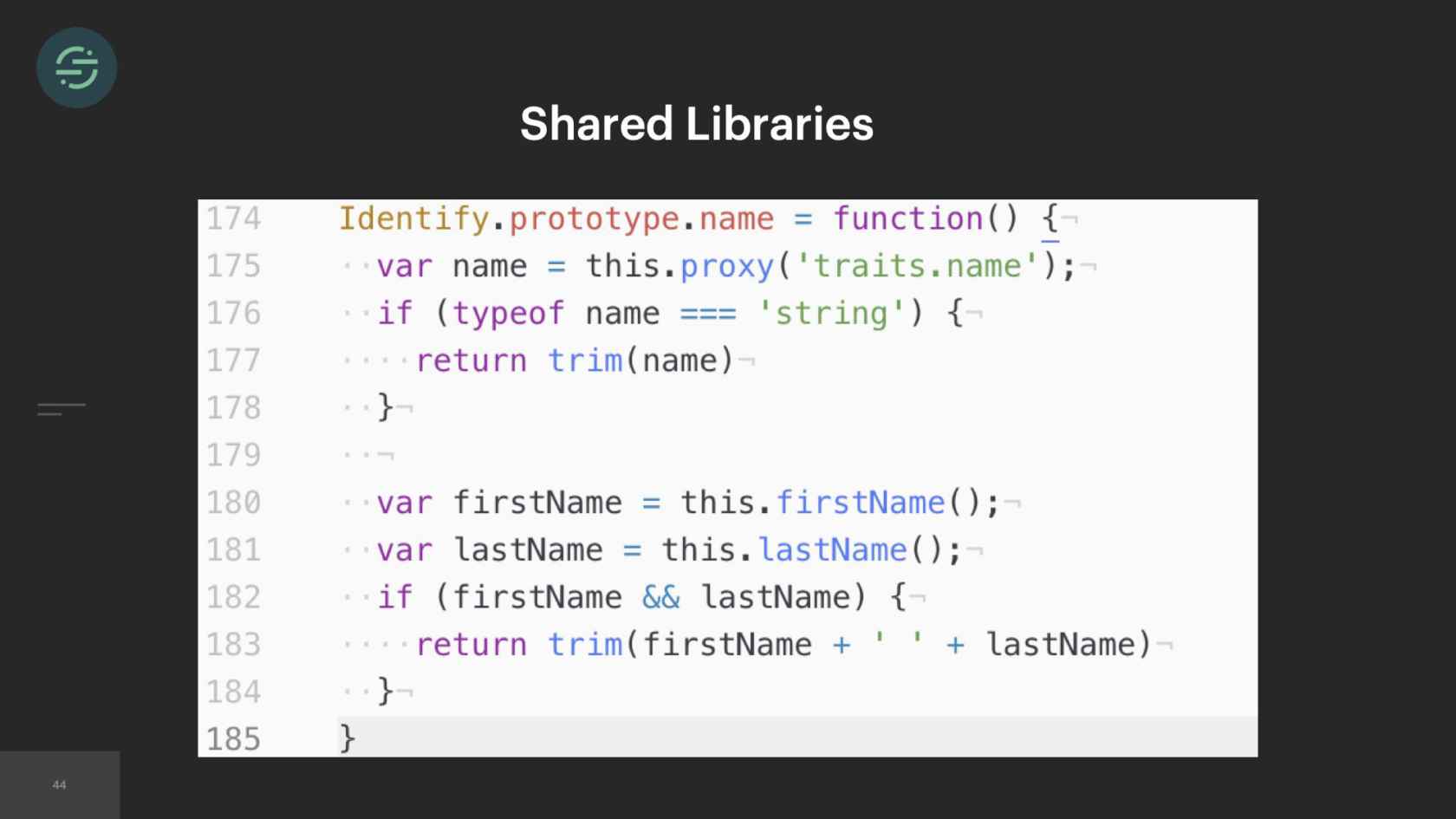
We wrote some shared libraries. Now for that name example, I could go into any of our destination code bases, call event.name. This is what would happen under the hood. The library would check for traits.name, that didn't exist. It would go through and check for first name and last name, checking all the cases. These familiar methods made the code bases a lot more uniform, which made maintenance less of a headache. I could go into any code base and quickly understand what was going on.
What happens when there's a bug in one of these shared libraries? Let's say, for argument's sake, that we forgot to check snake_case here. Any customer that is sending us an event.snake_case won't have the name of their users in their end tools. I go into the shared library. Write a fix for it to start checking snake_case. I release a new version of it. All of our infrastructure at the time was hosted on AWS. We were using Terraform to manage the state of it. The state of our infrastructure lived in GitHub. This was the standard deploy process for just one of these services. If everything went perfectly smoothly, I could probably get this change out to one service in about an hour. We had over 50 new destinations now, which meant 50 new queues and 50 new services. If I wanted to get this fix out to just check snake_case on a name, I now had to test and deploy dozens of services. With over 50 destinations, that's at least one week of work for me to get this change out, or the whole team is with me heads down in a room and we're powering through these destinations.
Changes to our shared libraries began to require a ton of time and effort to maintain. Two things started happening because of that. One, we just stopped making changes to our shared libraries even when we desperately needed them. It started to cause a lot of friction in our code base. The second was, I would go in and just update the version in that specific destination code base. Because of that, eventually, the versions of our shared libraries started to diverge across these code bases. That amazing benefit we once had of reduced customization, completely reversed on us. Eventually, all of our destinations were using different versions of these shared libraries. We probably could have built tooling to help us with testing and automating the deploys of all of these services. Not only was our productivity suffering because of this customization, we were starting to run into some other issues with our microservices.
Destination Traffic
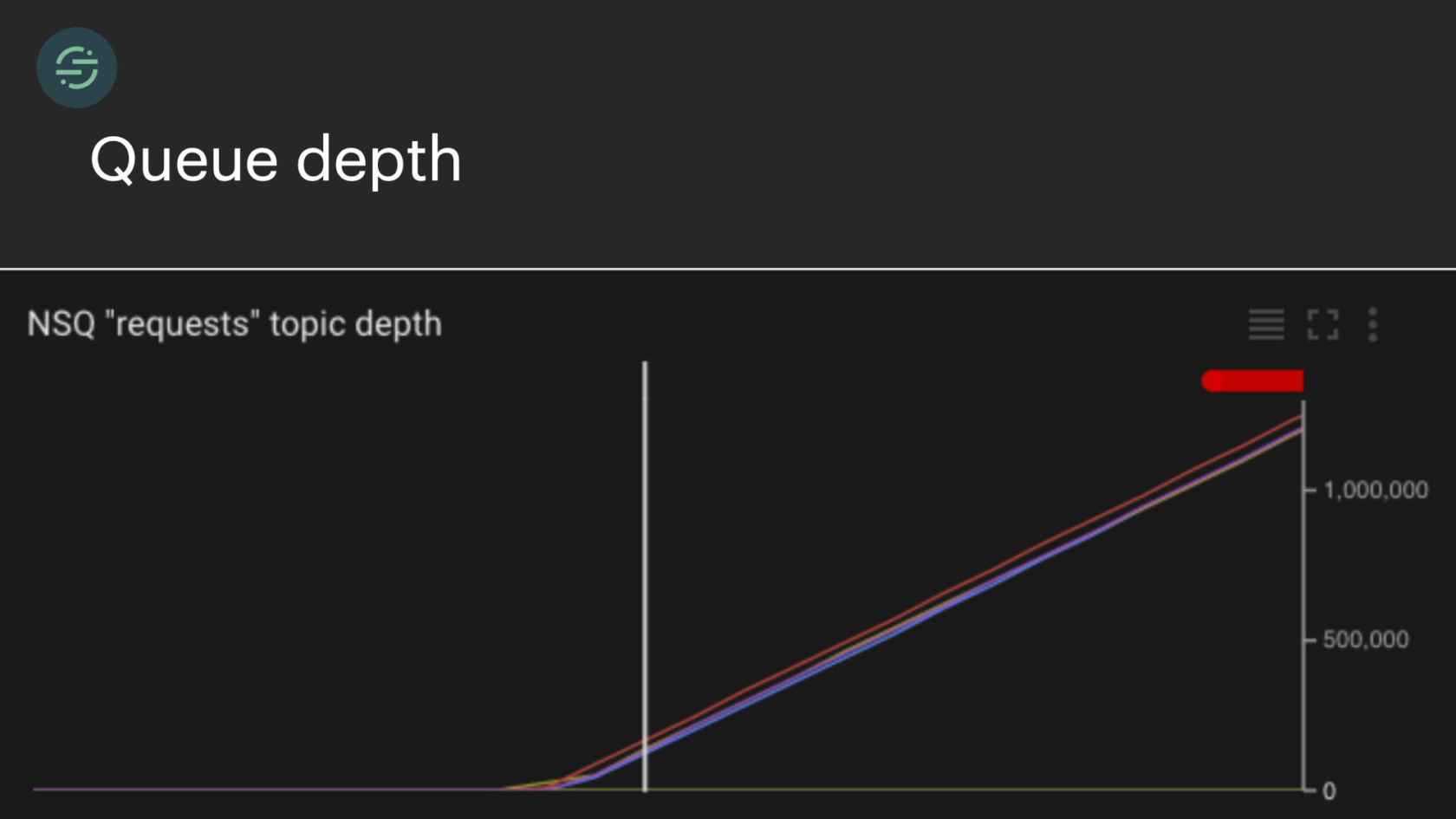
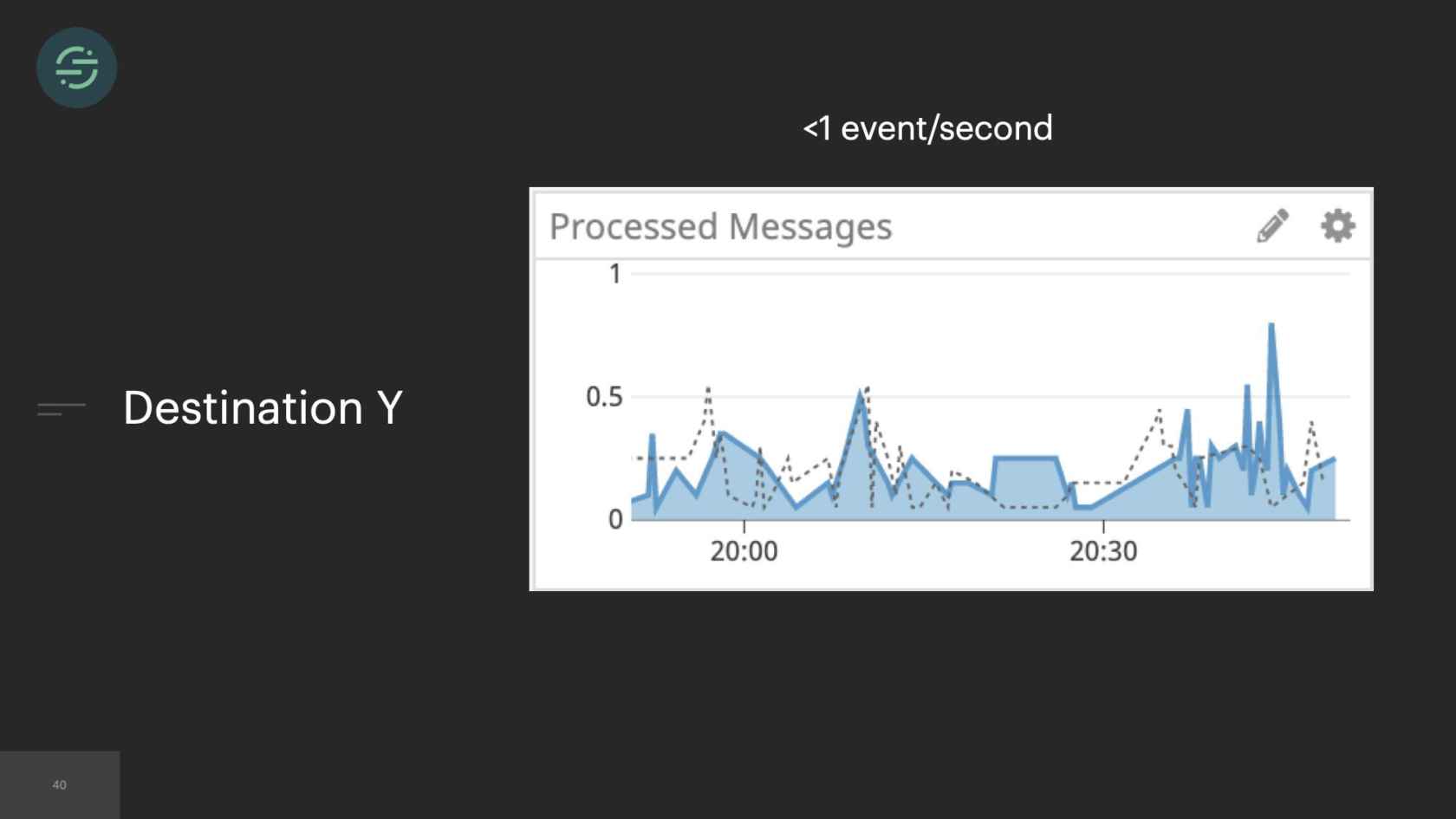
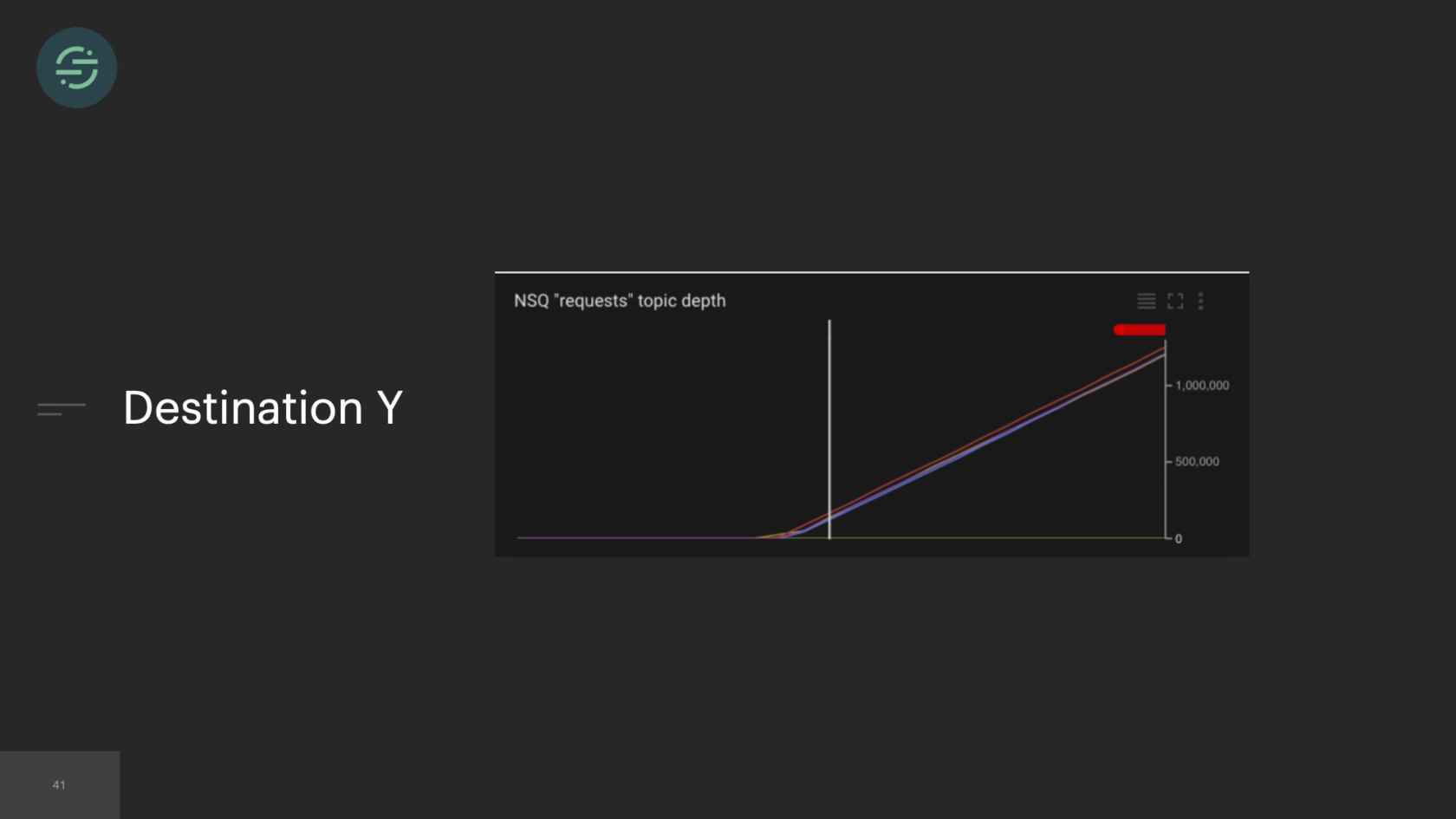
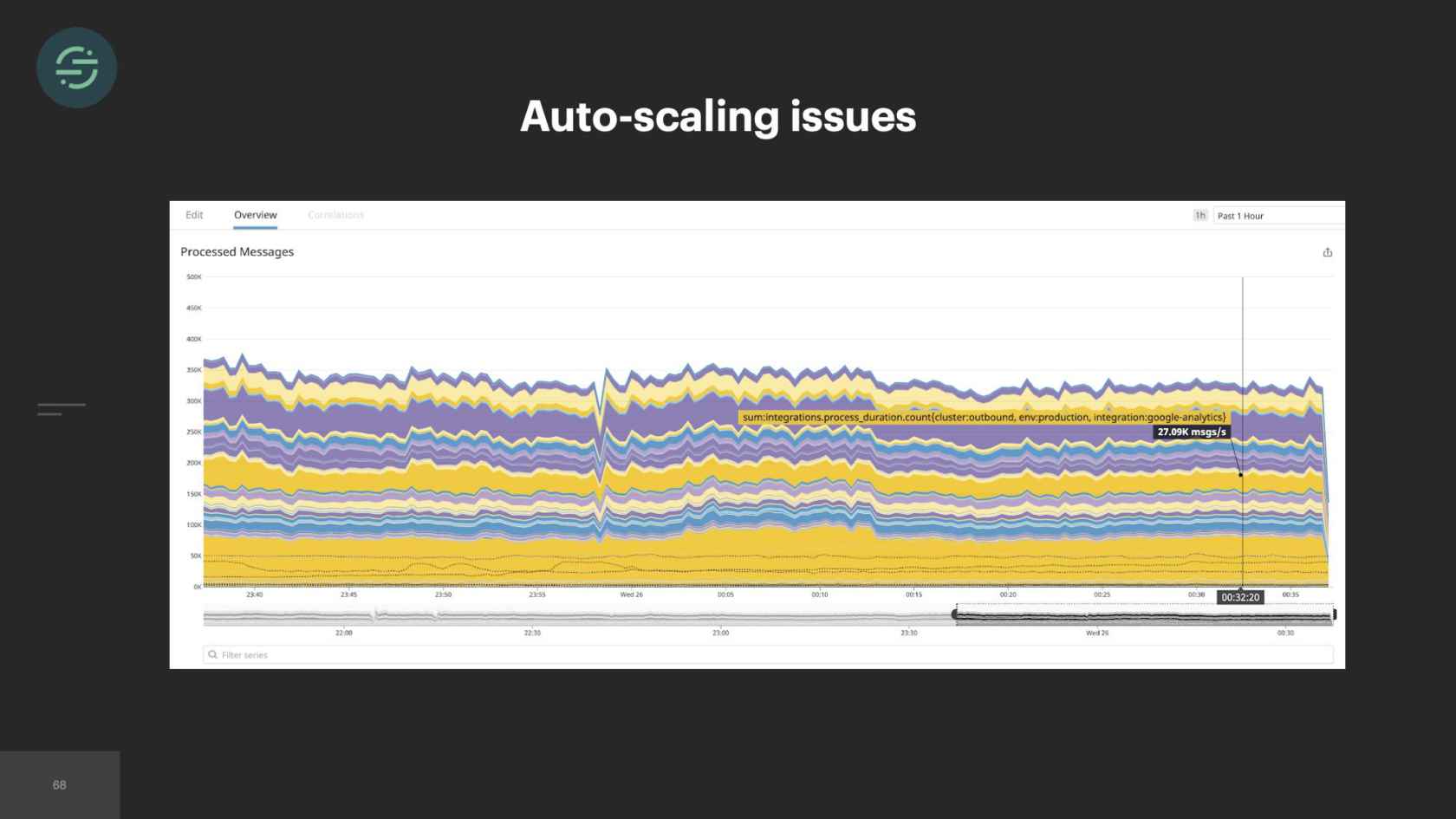
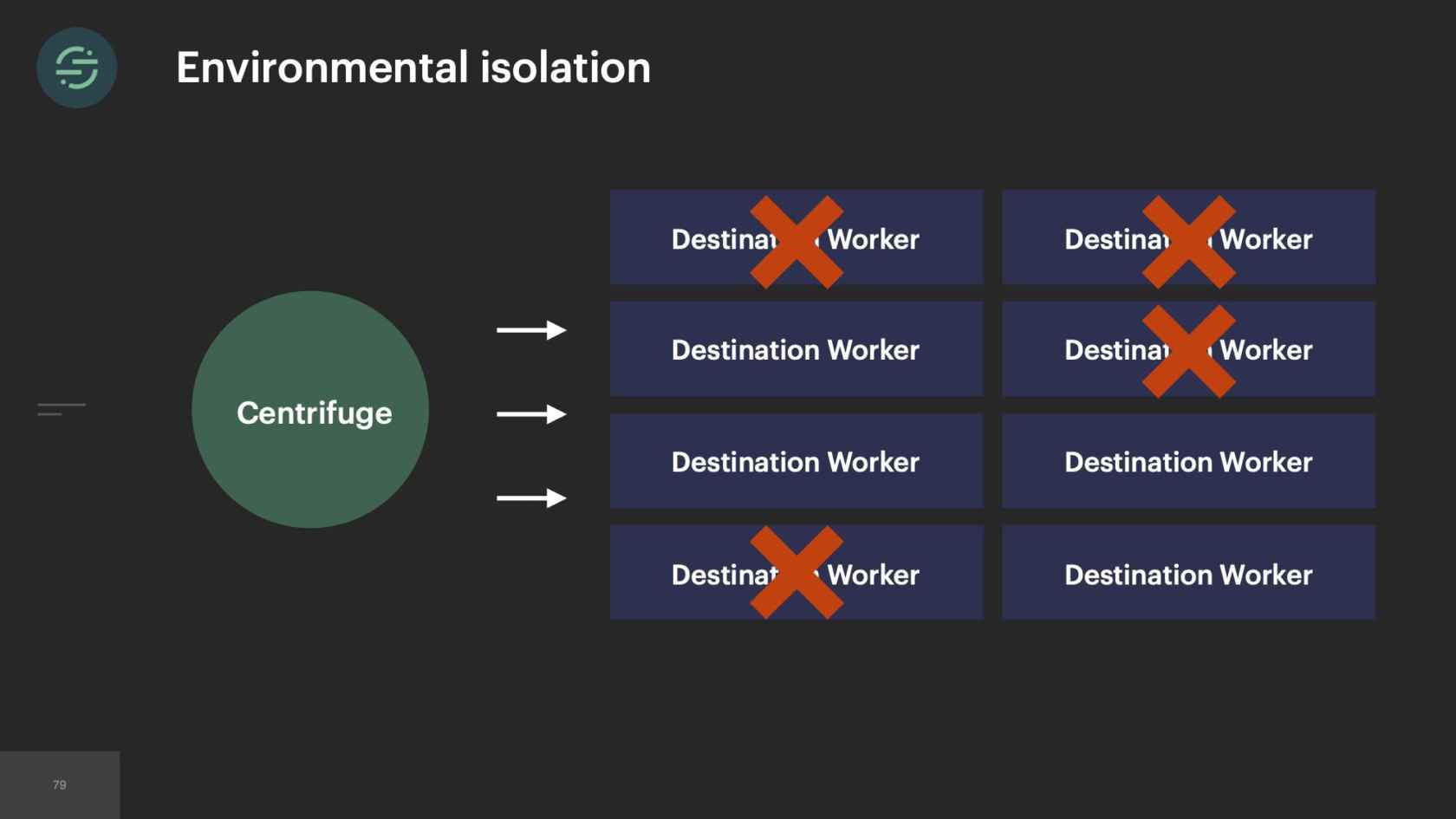
Something that we noticed was that some of our destinations were handling little to no traffic. For example, you have destination Y here, and they're handling less than one event per second. One of our larger customers who is sending us thousands of events per second, sees destination Y, wants to try it out. They turn on destination Y. All of a sudden, destination Y's queue is flooded with these new events, just because one customer enabled them. I'm getting paged to have to go in and scale up destination Y. Because similar to before, it outpaced our ability to scale up and handle this type of load. This happened very frequently.
At the time, we had one auto-scaling rule applied to all of these services. We would play around with it to try and master the configuration to help us with these load spikes. Each of these services also had a distinct amount of CPU and memory resources that they used. There wasn't really any set of auto-scaling rules that worked. One solution to this could be to just overprovision and just have a bunch of minimum workers in the pool. That gets expensive. We'd also thought about having dedicated auto-scaling rules per destination worker, but we were already drowning in the complexity across the code bases. That wasn't really an option for us.
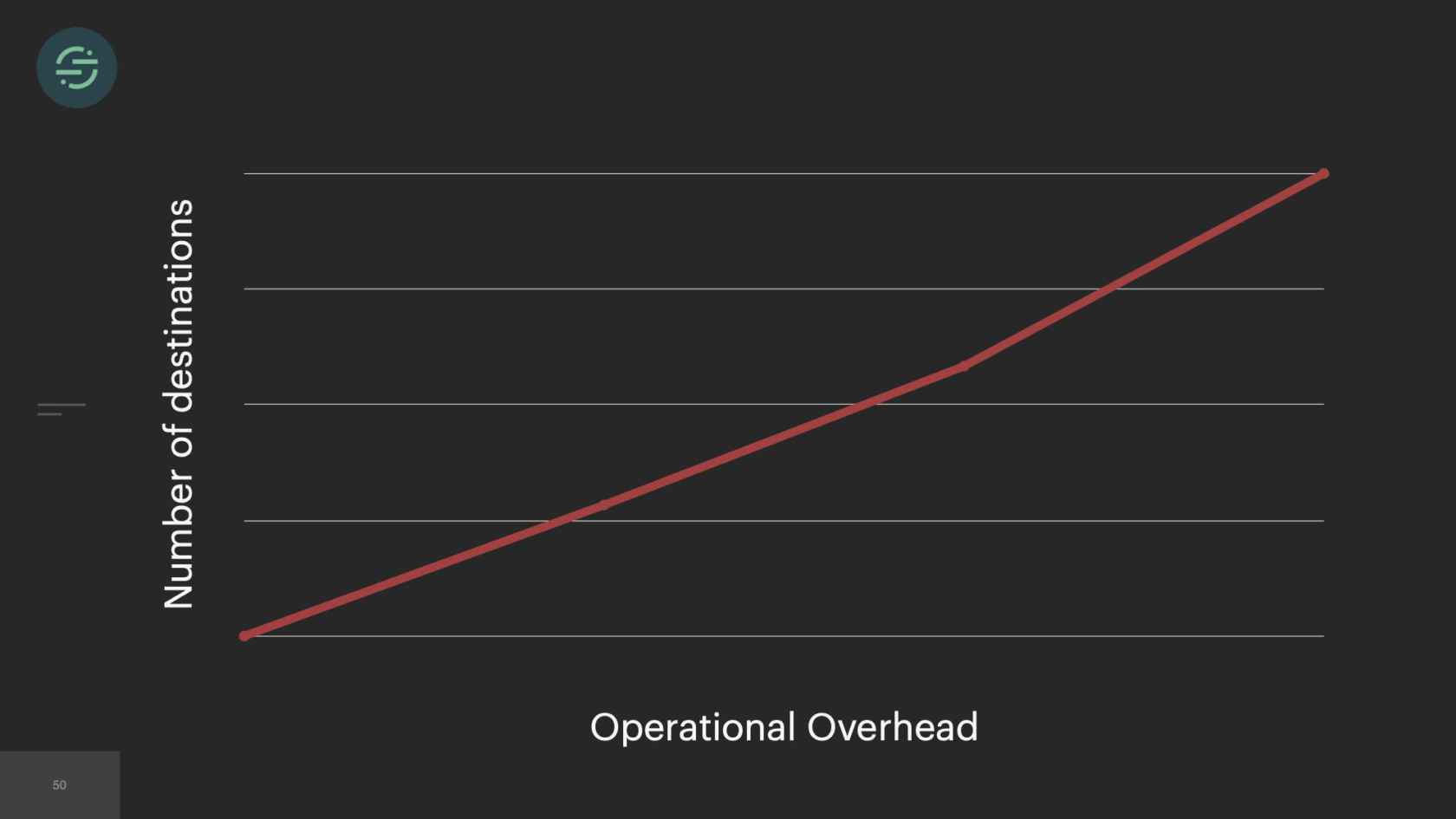
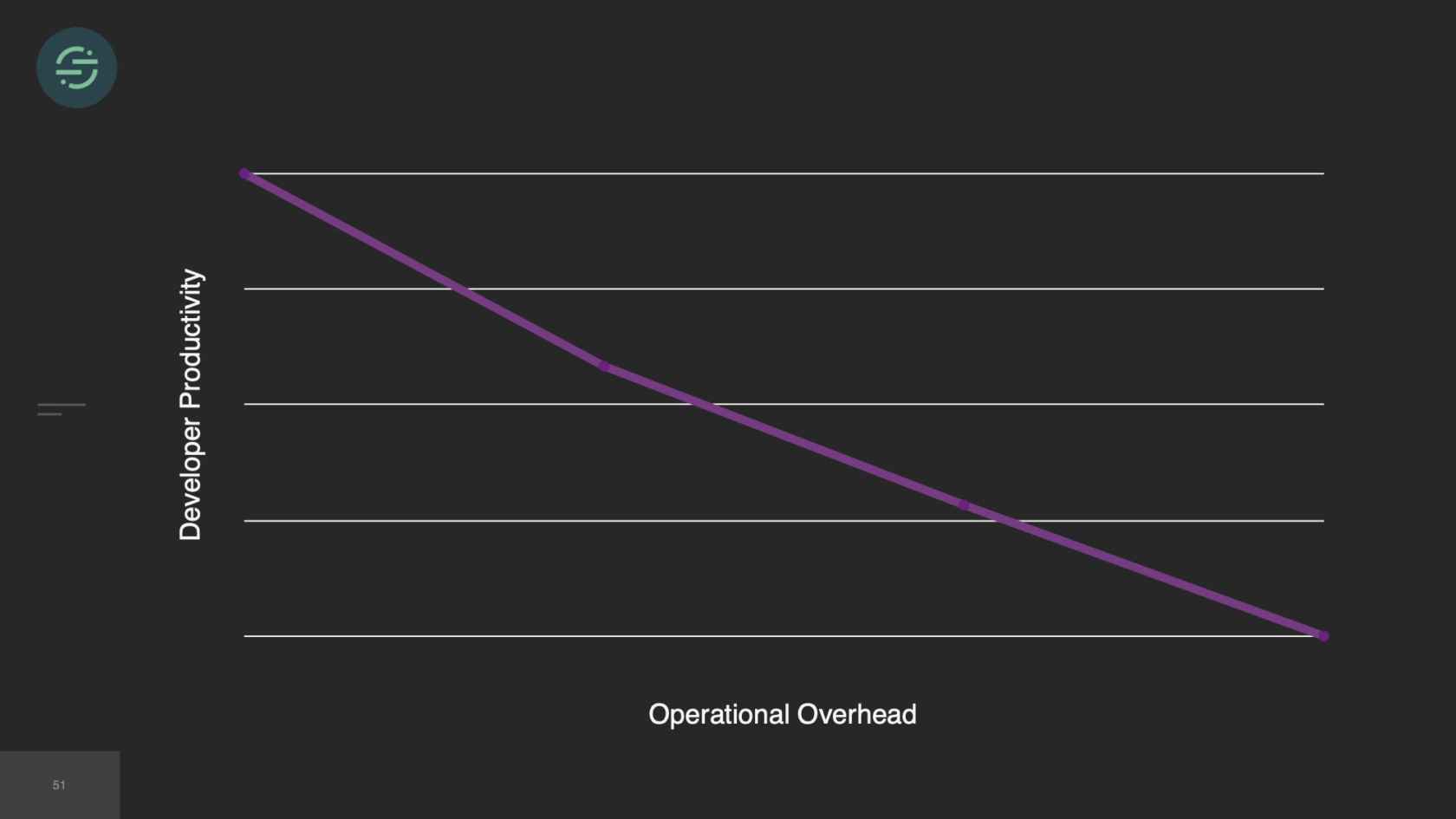
As time goes on, we're still adding to our microservice architecture, and we eventually hit a breaking point. We were rapidly adding new destinations to this platform. On average, it was about three per month. With our setup, our operational overhead was increasing linearly with each new destination added. Unless you're adding more bodies to the problem, what tends to happen is your developer productivity will start to decrease as your operational overhead increases. Managing all of these services was a huge tax on our team. We were literally losing sleep over it, because it was so common for us to get paged to have to go in and scale up our smaller destinations. We'd actually gotten to a point where we'd become so numb to pages on issues that we weren't responding to them as much anymore. People were reaching out to our CEO to be like, "What is going on over there"?
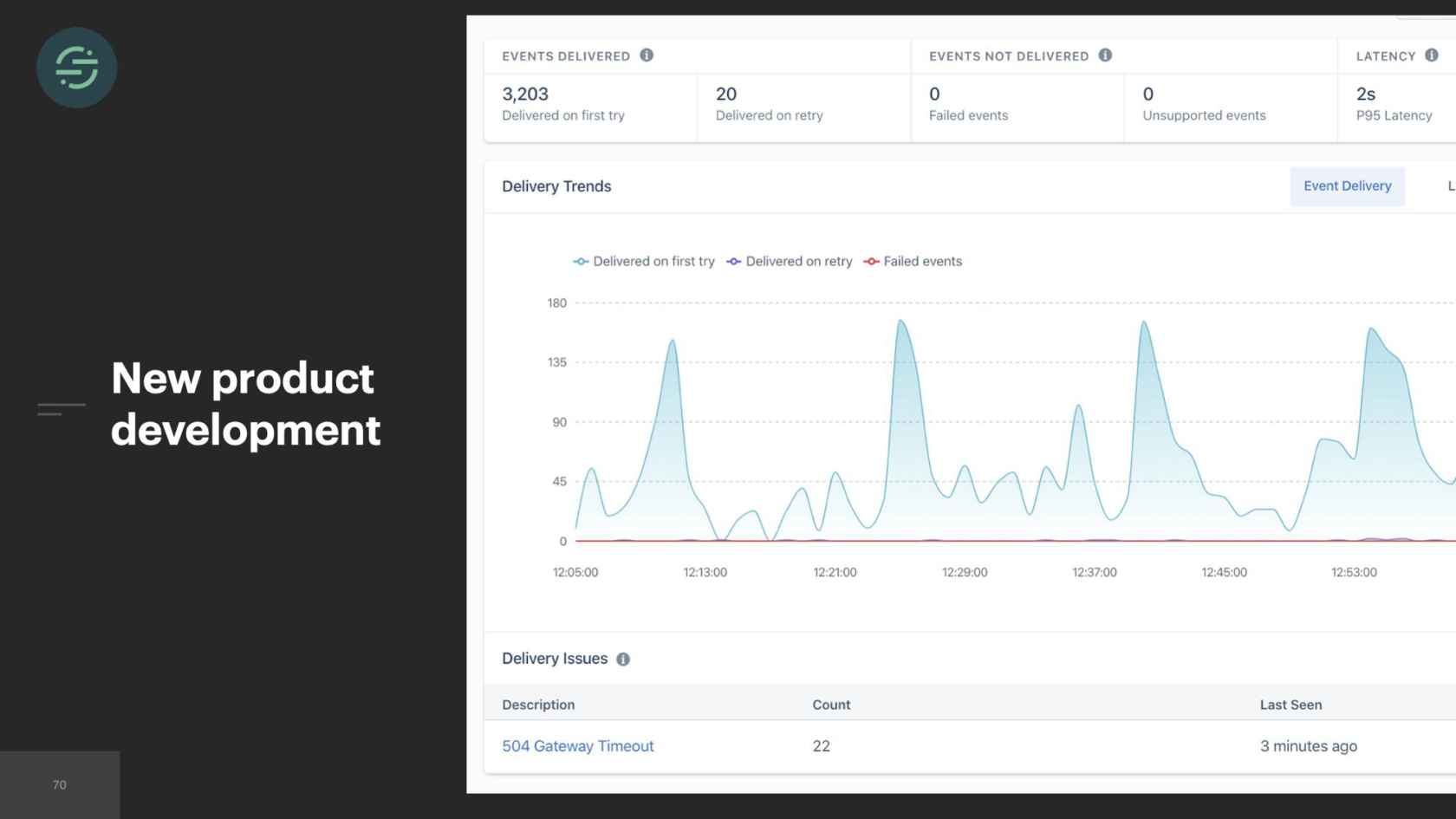
Not only did this operational overhead cause our productivity to decline, but it also halted any new product development. A really common feature request we got for our destinations was customers wanted to understand if their events were successfully sent to the destination or not. At the time, our product was a bit of a black box. We'd given customers visibility into whether their event had made it to our API, like I'm showing you here. Then if they wanted to know if their events had made it to their destination, they'd have to go into that destination and check for themselves. The solution for that in our microservice world would have been to create a shared library that all the destinations could use to easily publish metrics to a separate queue. We were already in that situation with our current shared libraries that were on different versions for each of these services. We knew that that was not going to be an option. If we ever want to make a change to that feature, we'd have to go through and test and deploy every single one of these services.
Microservices Trade-offs
If we take a look now at the trade-offs, the operational overhead is what is killing us. We're struggling just to keep this system alive. This overhead of managing this infrastructure is no longer maintainable and was only getting worse as we added new destinations. Because of this, our productivity and velocity was quickly declining. The operational overhead was so great that we weren't able to test and deploy these destinations like we needed to, to keep them in sync, which resulted in the complexity of our code bases exploding. Then new product development just didn't happen on the platform anymore. Not only because we were drowning, just trying to keep the system alive, but because we knew that any additions that we made would make the complexity worse. When we started to really think about it, microservices didn't actually solve that fundamental head-of-line blocking problem in our system, it really just decreased the blast radius of it.
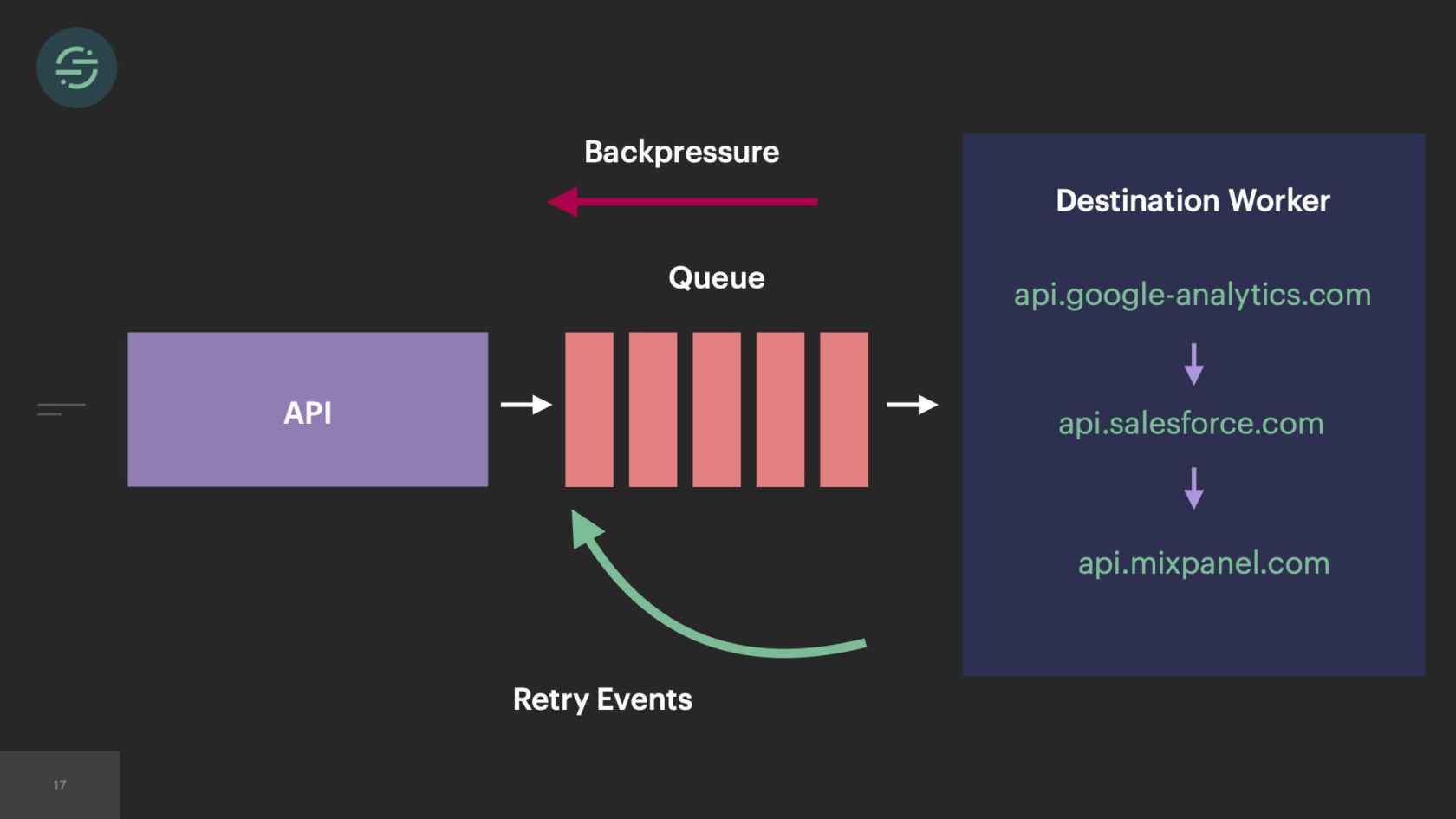
If you look at our individual queue now, we still have new events in line with retry events. It's 2017, we have some pretty large customers that are sending a ton of events. Then we also are now supporting some destinations, who can only handle about 10 requests a minute. Rate limiting was something we were constantly dealing with across all our destinations. Rate limiting is an error that we want to retry on. One customer's rate limits would cause delays for all of our customers using that destination. We still have this head-of-line blocking issue. It's now just isolated at the destination level.
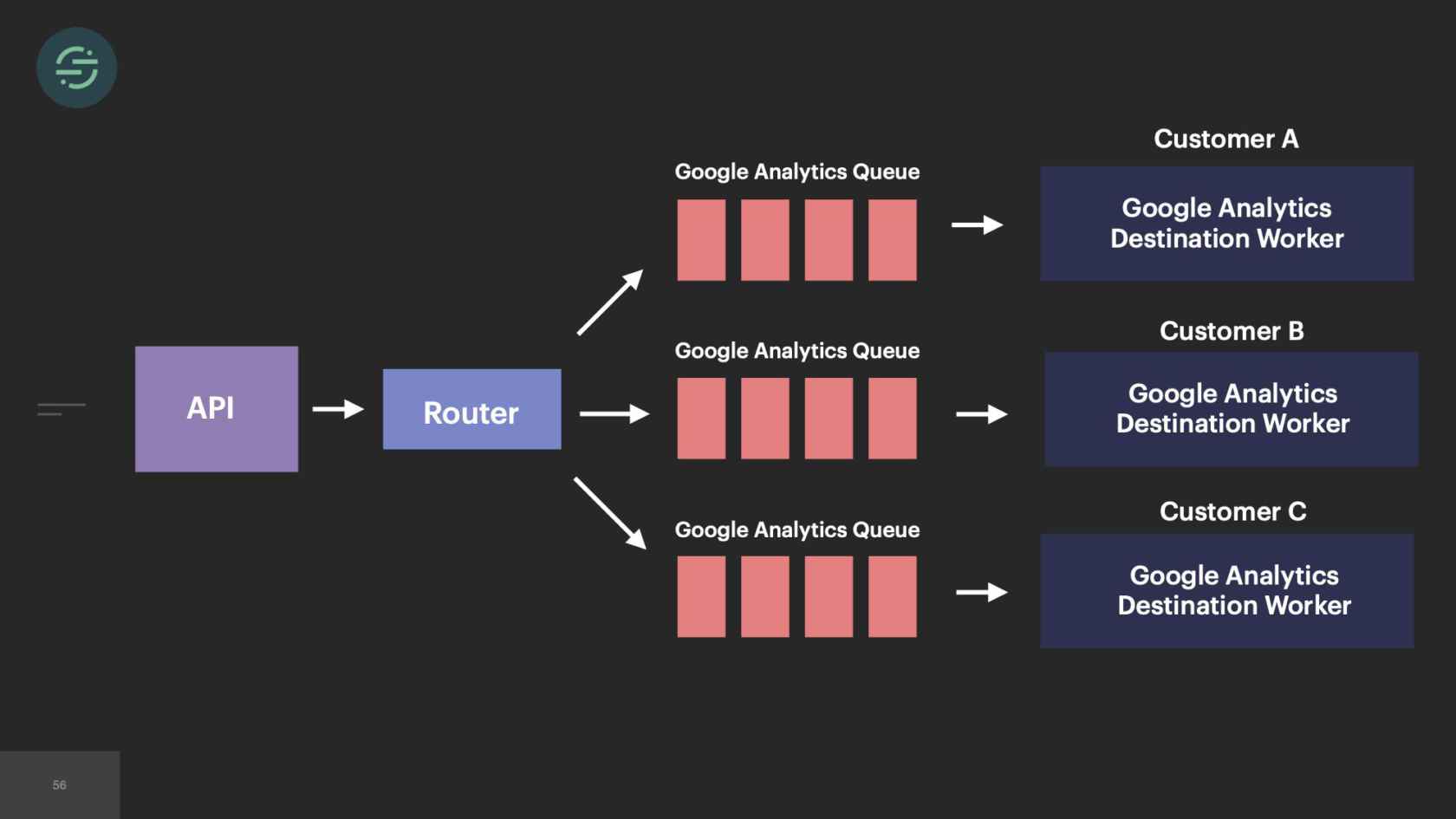
The ideal setup to actually solve for that issue in our microservice world would have been one queue and one destination worker per customer per destination. Since we were already reaching our breaking point with microservices, that was not an option. I'm not talking about adding a couple hundred more microservices and queues. I'm talking tens of thousands of more microservices and queues.
It's 2017 now, and we have officially reached the breaking point. At this point, we have over 140 services and queues and repos. The microservice setup that originally allowed us to scale is now completely crippling us. We brought on one of our most senior engineers to help us with the situation. This is the picture that he drew to depict what the situation was we're in. In case you can't tell, that's a big hole in the ship, and there's three engineers struggling to ship water out of it. It's what it felt like.
Moving Back To a Monolith
The first thing that we knew we wanted to do was we wanted to move back to a monolith. The operational overhead of managing all these microservices was the root of all of our problems. If you look at the trade-offs, the burdens of this operational overhead was actually outweighing all of the benefits that microservices gave us. We'd already made the switch once before. This time, we actually knew that we had to really consider the trade-offs that were going to come with it, and think deeply about each one, and be comfortable with potentially losing some of the benefits that microservices gave us.
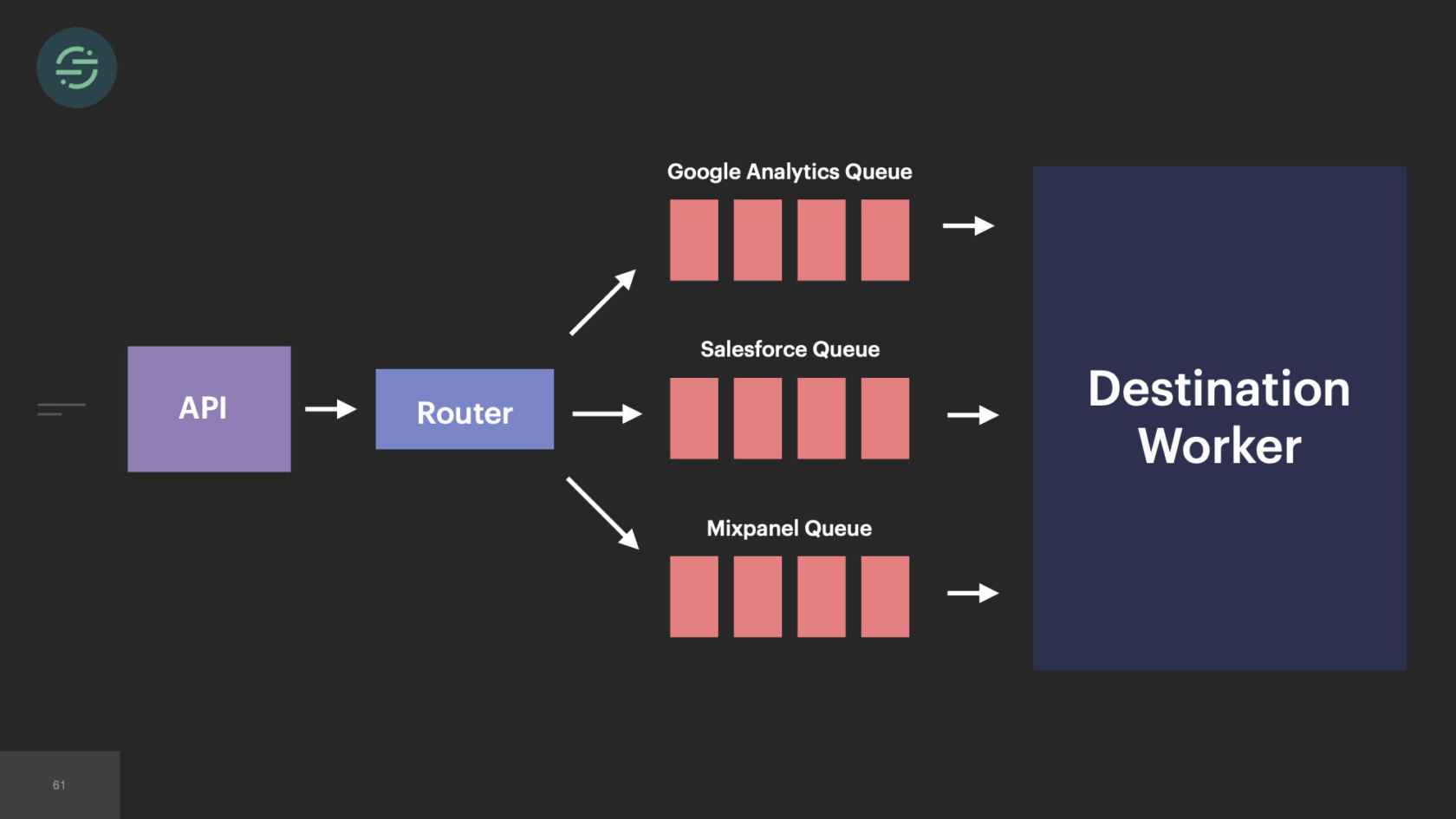
We knew we wanted to move everything back into a service, but the architecture at the time would have made that a bit difficult. If we'd put everything in one service but kept the queues, now this monolithic destination worker would have been responsible for checking each queue for work. That would have added a layer of complexity to the destinations with which we weren't comfortable with. It also doesn't solve that fundamental head-of-line blocking issue that we see. One customer's rate limits can still impact everybody using that destination. Moving back to a single queue puts us back in the same situation we were in when we first launched, where now one customer's retries impact all destinations and all customers.
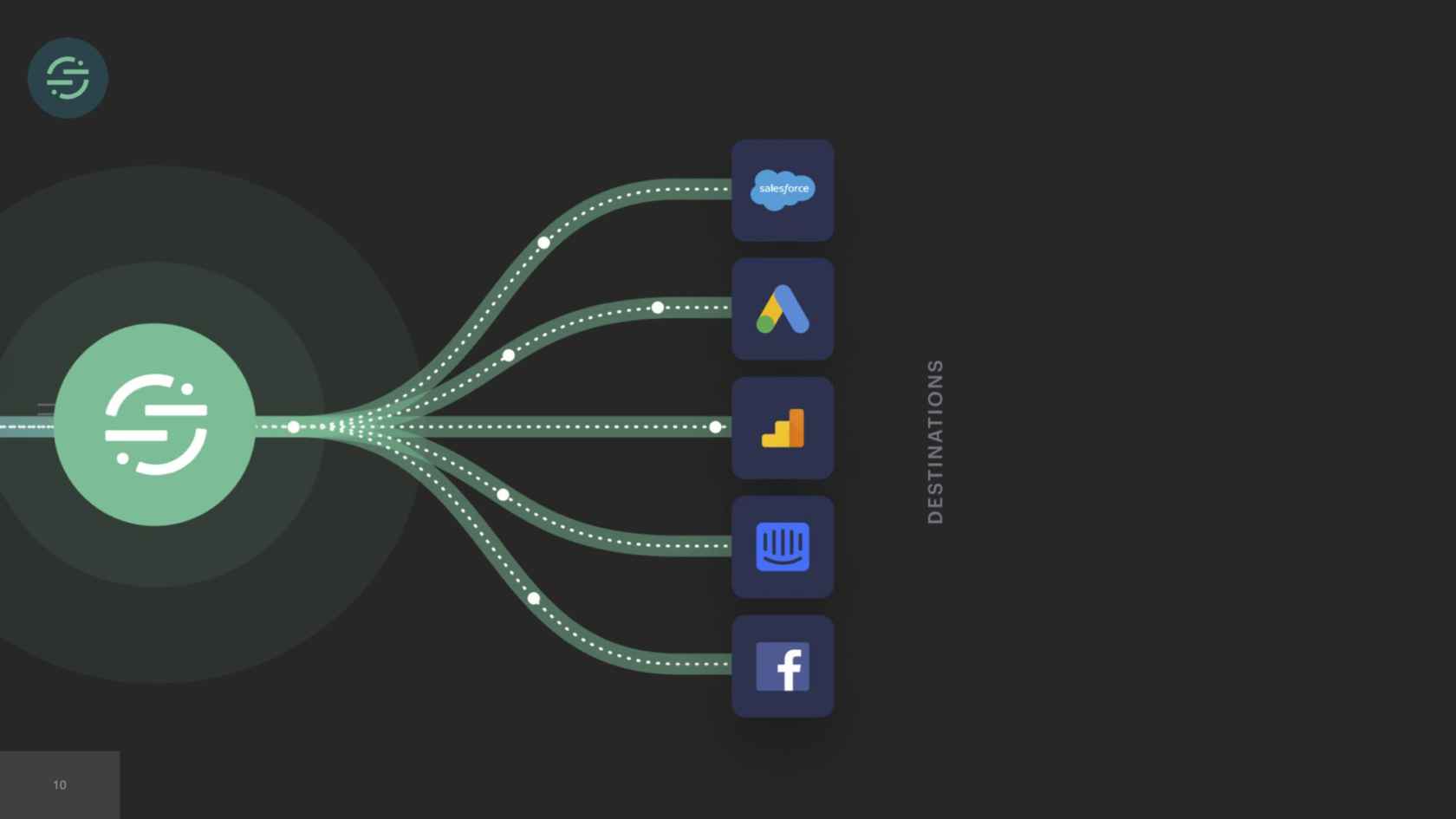
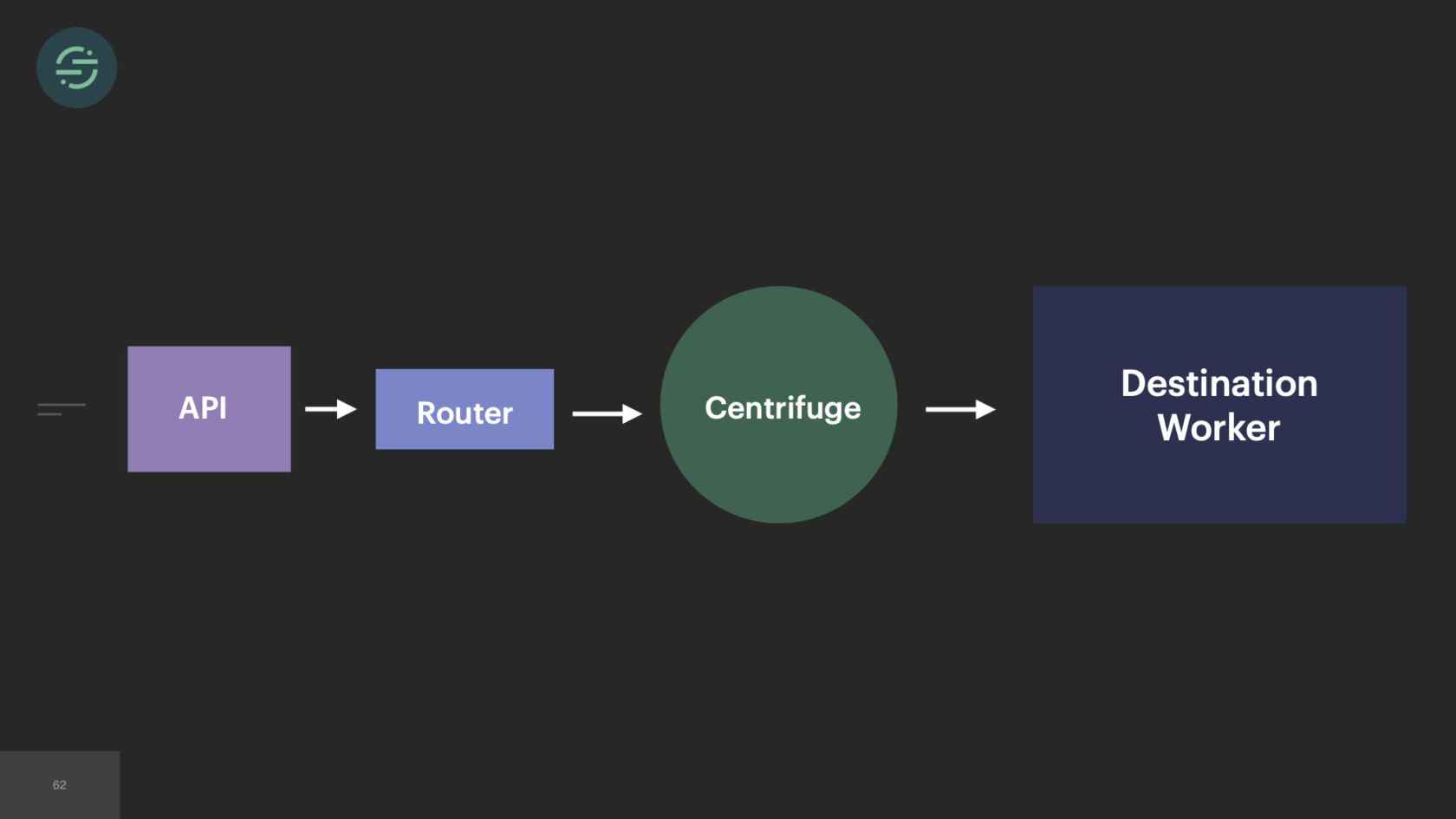
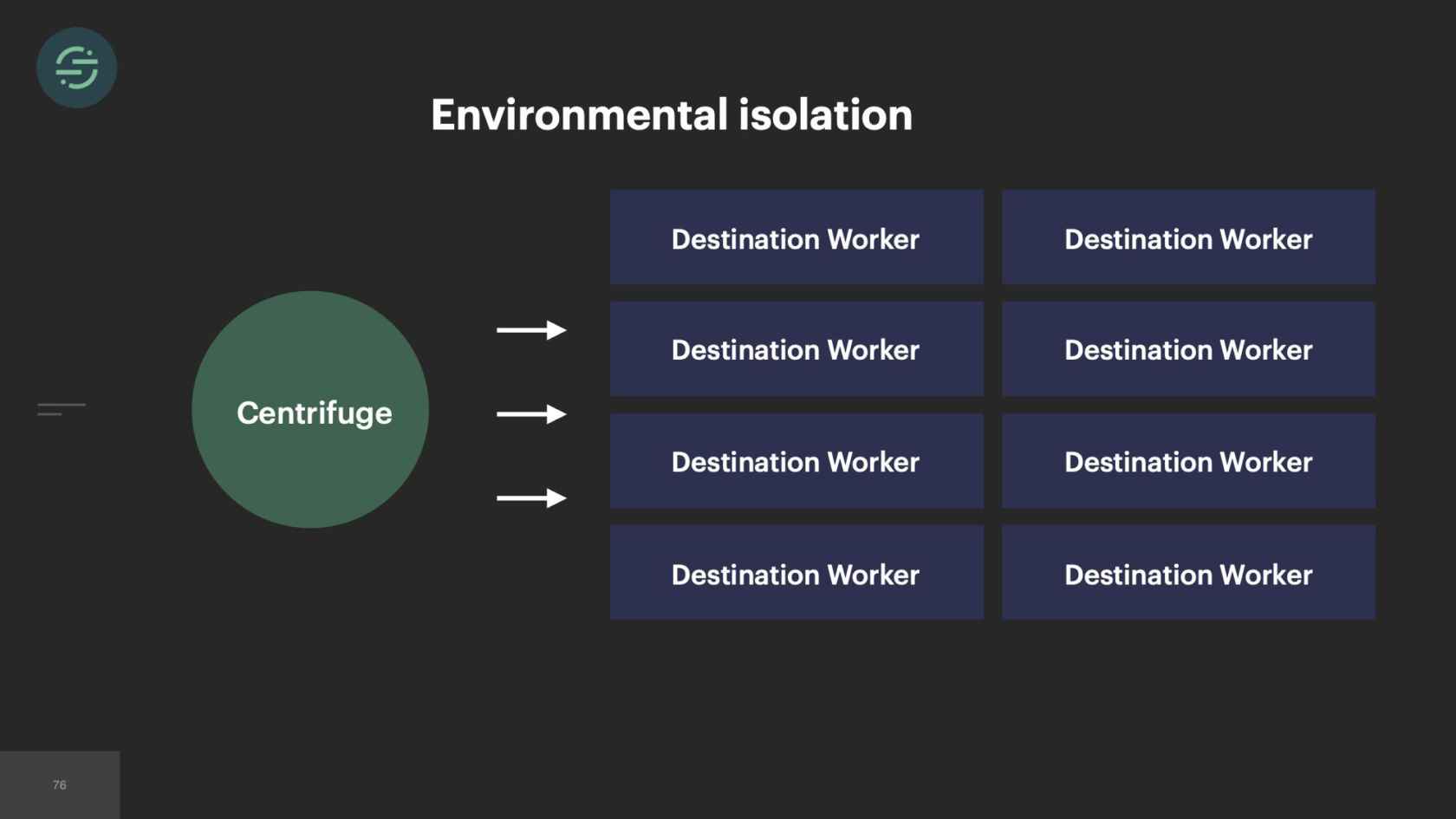
This was the main inspiration for Centrifuge. Centrifuge would replace all of our queues and be responsible for sending events to this single monolithic worker. You could think of Centrifuge as providing a queue per customer per destination but without all the external complexity. It finally solved that head-of-line blocking issue that we'd experienced since we launched once and for all. Now the destinations team, there's about 12 of us. We are dedicated to just building Centrifuge and this destination worker. After we'd designed the system, we were ready to start building. We knew that since we were going to go back to one worker, we wanted to move back to a mono-repo. This specific part of the project we called it the great mono-gration.
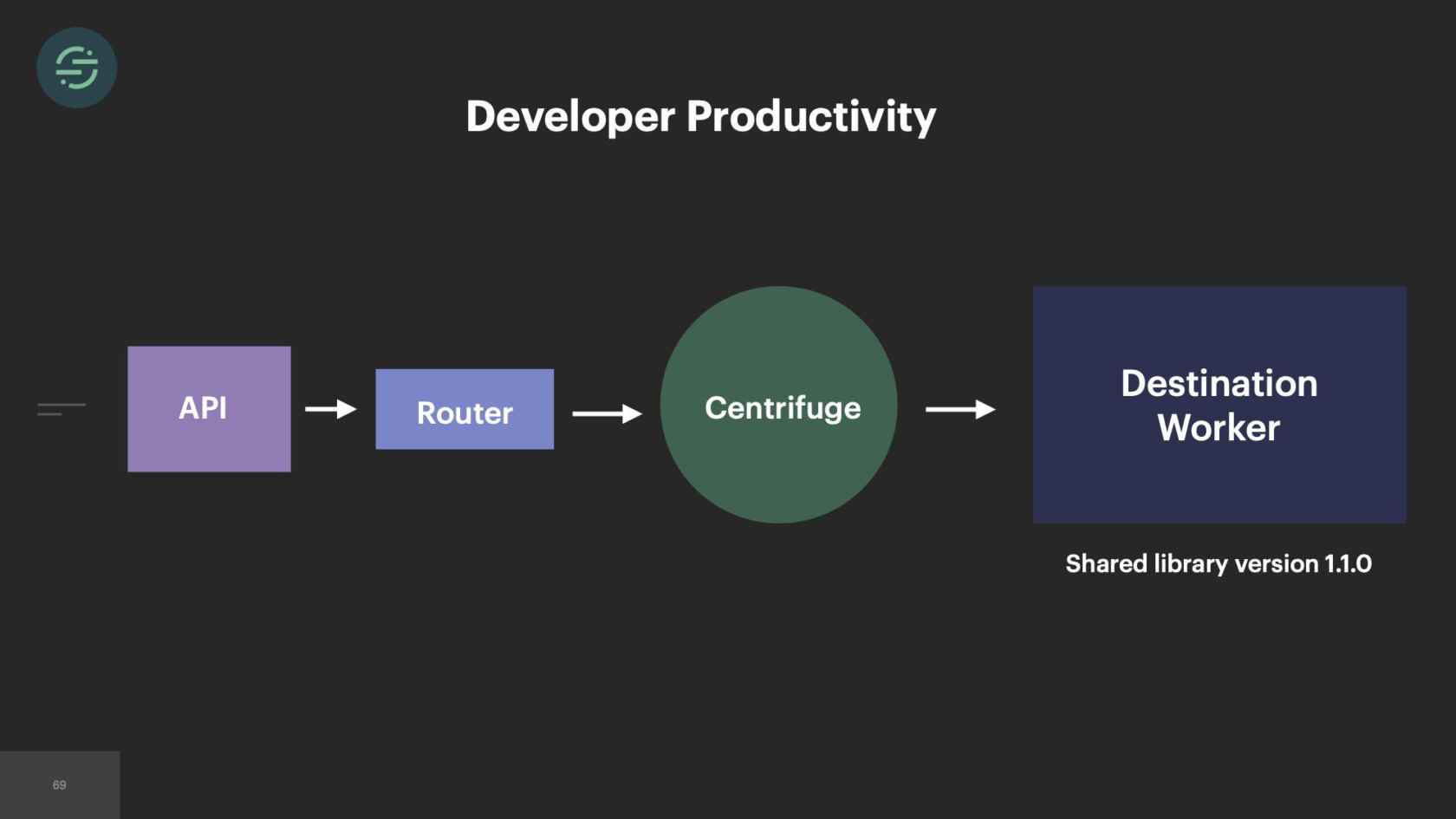
The destinations were divided up amongst each of us. We started porting them over back into a mono-repo. With this change, we saw an opportunity to fix two fundamental issues. One, we were going to put everything back on the same versions of our dependencies. At this point, we had 120 unique dependencies. We were committed to having one version of the shared dependency. As we moved destinations over, we'd update to the latest. Then we'd run the tests and fix anything that broke.
Building a Test Suite
The next part of the mono-gration, this is really the meat of it, was, we needed to build a test suite that we could quickly and easily run for all of our destinations. The original motivation for breaking destinations out into their own repos was these failing tests. This turned out to be a false advantage. Because these destination tests, were actually making outbound HTTP requests over the internet to destination APIs to verify that we're handling the requests and responses properly. What would happen is I would go into Salesforce, which hadn't been touched in six months, and need to make a quick update. Then the tests are failing because our test credentials are invalid.
I go into our shared tool and I try and find updated credentials, and of course they're not there. Now I have to reach out to our partnerships' team or Salesforce directly to get new test credentials, just so I can get out my small change to Salesforce. Something that should have taken me only a few hours is now taking me over a week of work because I don't have valid test credentials. Stuff like that should never fail tests. With the destinations broken out into separate repos, there was very little motivation for us to go in and clean up these failing tests. This poor hygiene led to a constant source of frustrating technical debt. We also knew that some destination APIs are much slower than others. One destination test suite could take up to five minutes to run, waiting for the responses back from the destination. With over 140 destinations, that means our test suite could have taken up to an hour to run, which was not acceptable.
Traffic Recorder
We built something called traffic recorder. Traffic recorder was responsible for recording and saving all destination test traffic. On the first test run, what it would do is the requests and responses were recorded to a file like this. Then on the next run, the request and response in the file is played back instead of actually sending the request to the destination API. All these files are checked into a repo as well, so that they're consistent with every change. That's made our test suite significantly more resilient, which we knew was going to be a must-have moving back to a mono-repo. I remember running the tests for every destination for the first time. It only took milliseconds, when most tests before would take me a matter of minutes, and it just felt like magic.
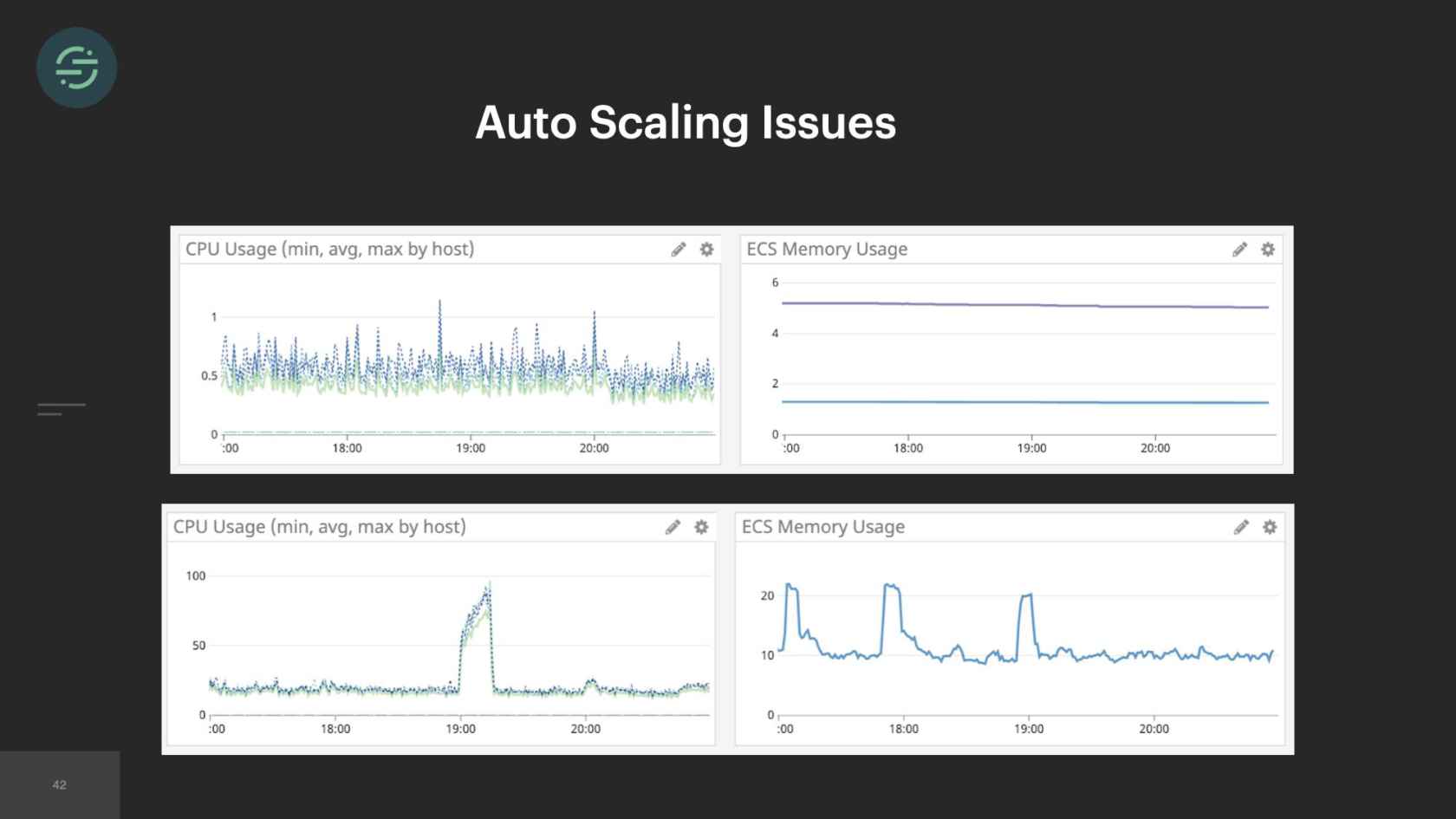
We finished the great mono-gration in the summer of 2017. Then the team shifts to focus on building and scaling out Centrifuge. We're slowly moving destinations over into the monolithic worker now as we're learning to scale Centrifuge. We complete this migration at the beginning of 2018. Overall, it was a massive improvement. If we look back at some of the auto-scaling issues that we had before, some of our smaller destinations weren't able to handle big increases in load. It was a constant source of pages for us. With every destination now living in one service, we had a good mix of CPU and memory intensive destinations, which made scaling a service to meet demand significantly easier. This large worker pool was able to absorb spikes in loads. We're no longer getting paged for the destinations that only handle a small number of events. We could also add new destinations to this and it wouldn't add anything to our operational overhead.
Next was our productivity. With every destination living in one service, our developer productivity substantially improved because we no longer had to deploy over 140 destinations to get a change out to one of our shared libraries. One engineer was able to deploy this service in a matter of minutes. All our destinations were using the same versions of the shared libraries as well, which significantly cut down on the complexity of the code bases. Our testing story was much better. We had traffic recorder now. One engineer could run the tests for every destination in under a minute, when making changes to the shared libraries. We also started building new products again. A few months after we finished Centrifuge and moved back to a monolith, myself and one other engineer were able to build out a delivery system for our destinations in only a matter of months.
Dealing With the Trade-offs
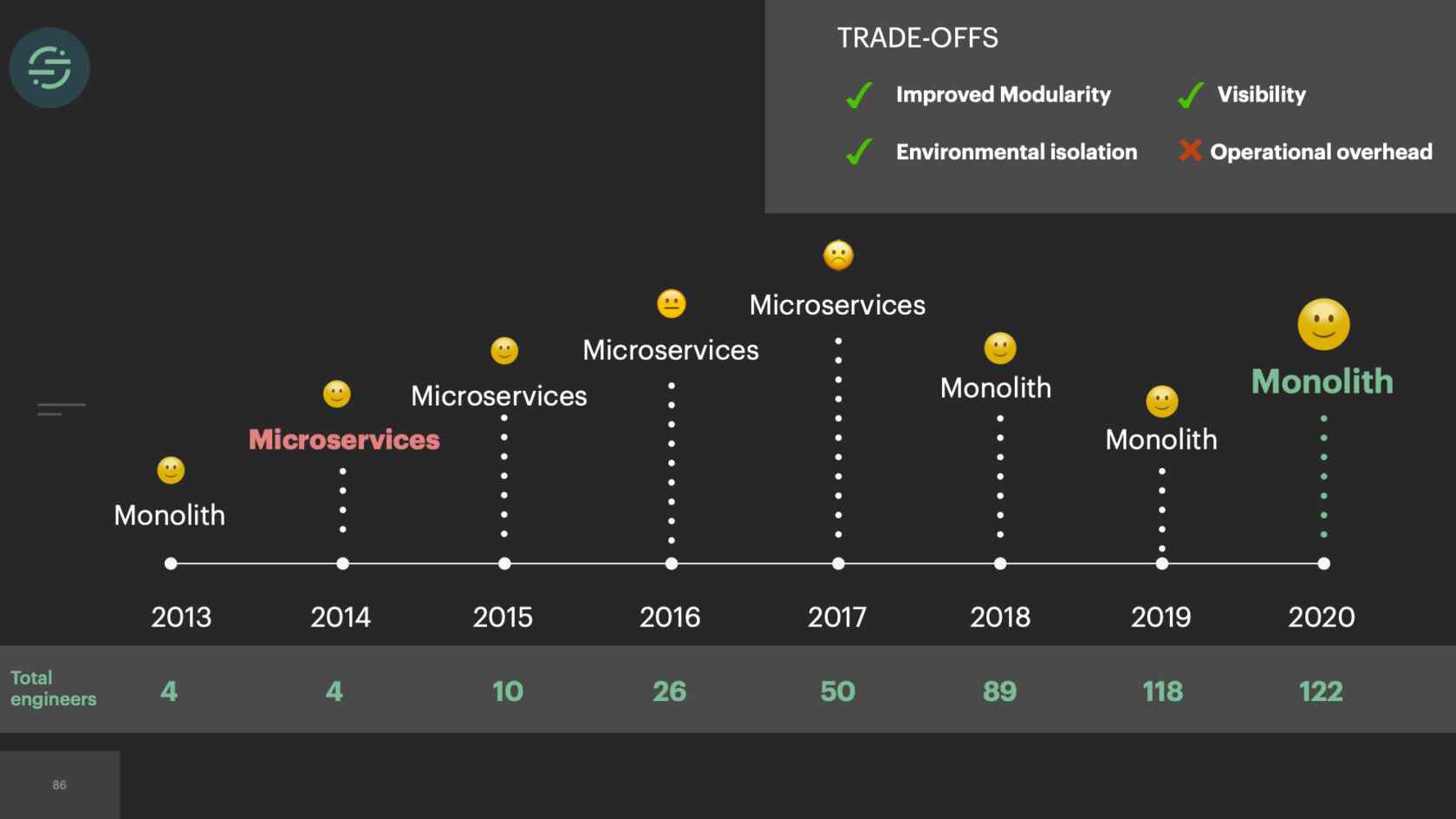
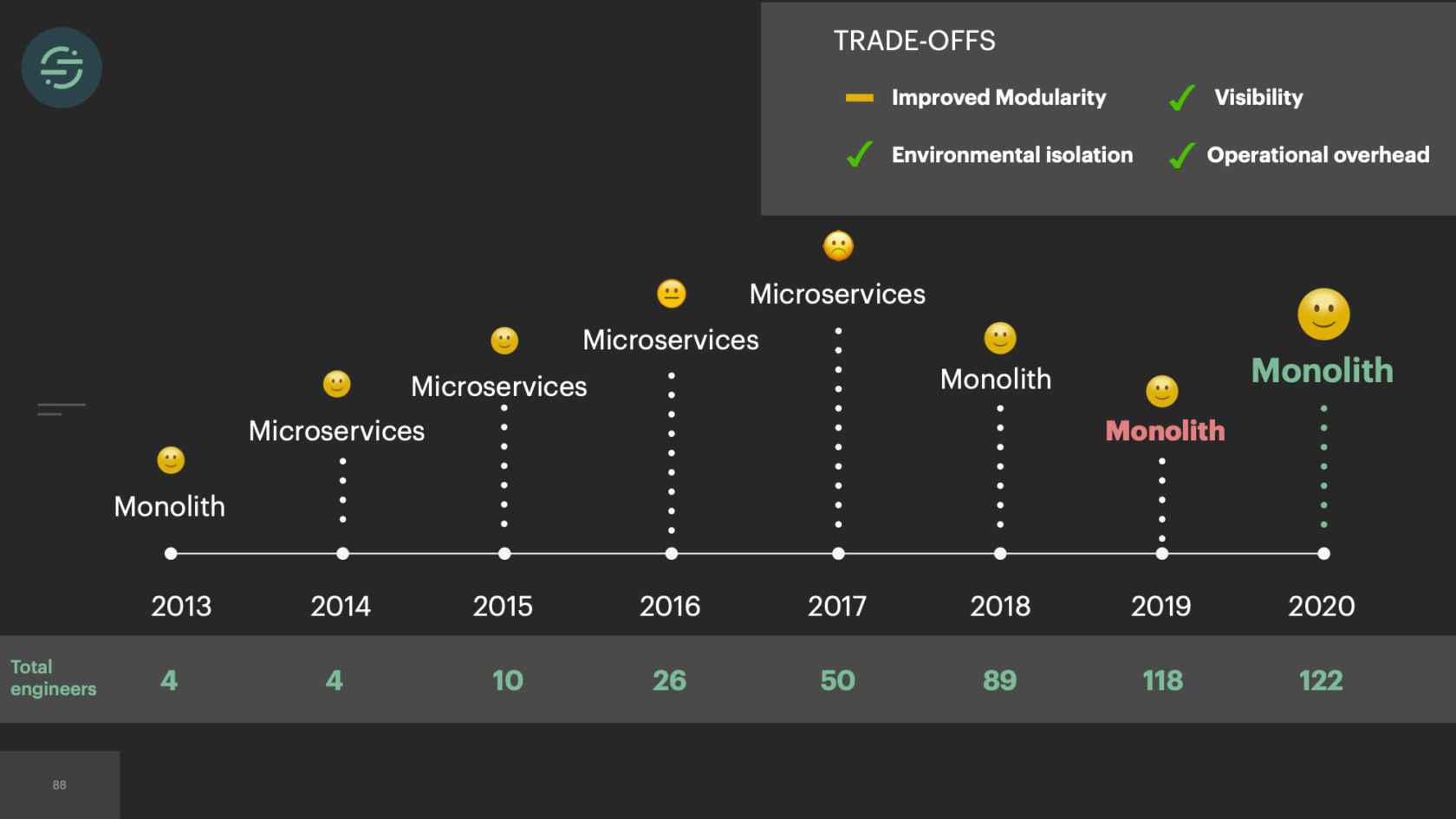
We're building new products again, and we're able to scale our platform without adding to our operational overhead. It wasn't all sunshine and roses moving back to a monolith. There were some trade-offs. If you take a quick, high-level look at the trade-offs, it doesn't look great. Our operational story had improved greatly. That was the root of all of our issues. We almost need a weight on here to signify how important each trade-off is. Traffic recorder had made us comfortable with the loss in improved modularity. Yes, if I had to go in and fix Salesforce and Marketo's tests are failing, I would have to fix those tests to get the change out. It made us more resilient to those types of failures that we saw in the beginning where invalid credentials would fail tests. Centrifuge fixed the head-of-line blocking issue, which was one of the main causes of environmental isolation. We actually ran into another issue with that. Then there was the default visibility that we no longer had, this was the first thing we ran into.
A few months after we moved to a monolith, we started seeing these destination workers running out of memory and crashing. This is commonly referred to as OOMKills. It wasn't happening in an alarming rate, but it was happening with enough frequency that we wanted to fix it. With our destination workers broken out into microservices before, we would have known exactly which destination was responsible, but now it was a bit more difficult.
OOM Debugging With Sysdig
To give you a sense of what we had to do now was we used this tool called Sysdig. Sysdig lets you capture and filter and decode system calls. We go on the host, and we run Sysdig monitoring these workers, and we think we find a connection link. We go in and we blindly make some updates to this service to fix this leak. Workers are still crashing. We didn't fix it. It took a few more weeks of different attempts and trying to almost blindly debug this memory issue.
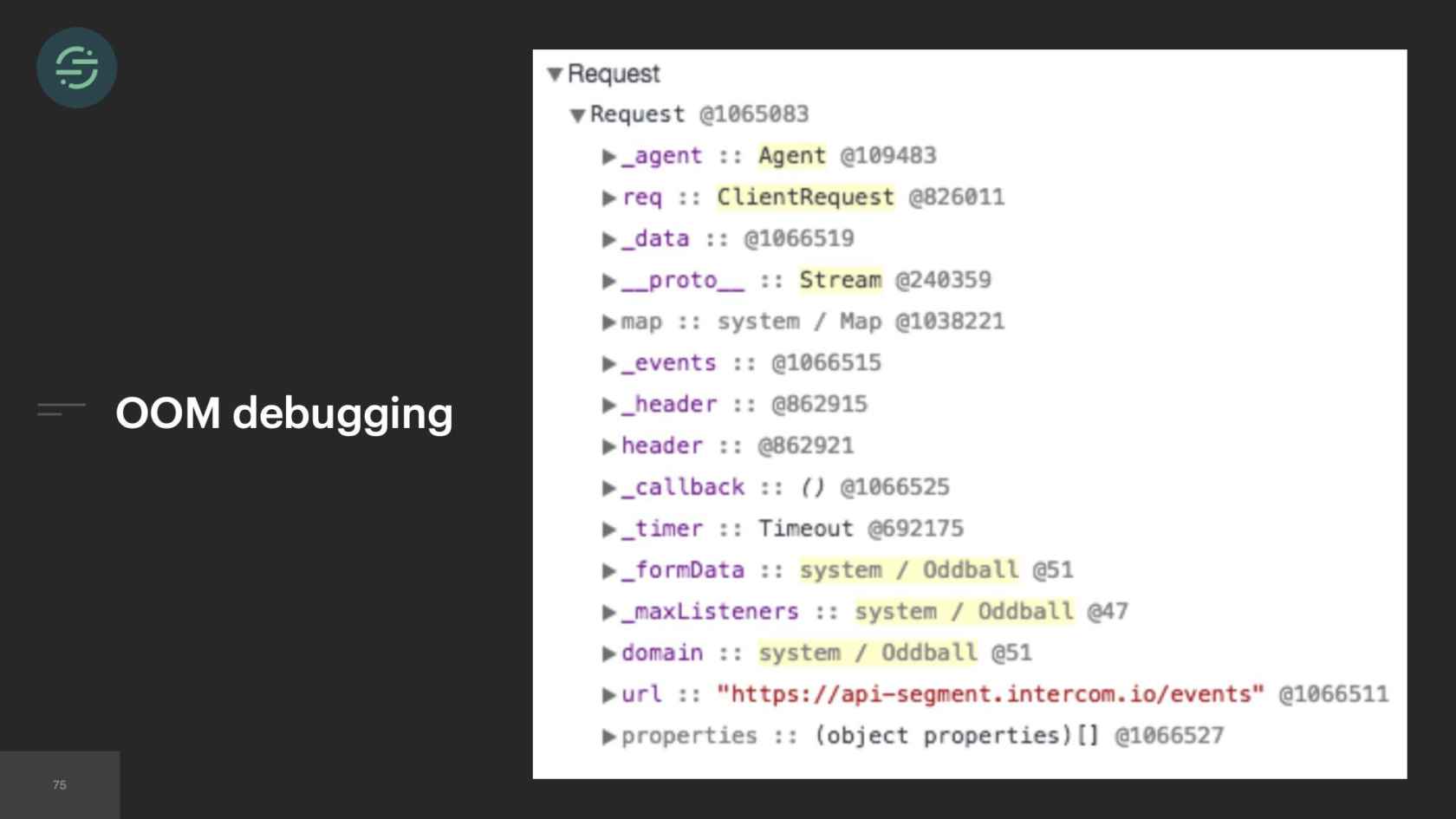
What ended up working was we used a package called node-heapdump. How that works is it synchronously writes a snapshot to a file on disk that you can later go and inspect with Google Chrome Dev tools. If you look really closely at the last two fields here, you'll see that the issue is in our intercom destination. For some reason, there's a 100 MB array. We know which destination it is. We're able to go and debug from there. It took some time and effort to implement this visibility into the worker that we got for free with microservices. We probably could have implemented something similar in our original monolith but we didn't have the resources on the team, like we did now.
Environmental isolation, this was the most frequent issue and unforeseen issue that we ran into moving back to a monolith. At any given time, we run about 2000 to 4000 of these workers in production. Something that we were constantly running into was, this worker is written in Node and we would constantly have uncaught exceptions. Uncaught exceptions are unfortunately common, and very easily can get into a code base undetected. For example, I remember, I was on-call one weekend and I happened to be in a different state with my whole family. It was my grandma's 90th birthday. We're all crammed into this hotel room. It's 2:00 a.m. on a Friday, and I'm getting paged. I'm like, "What could this possibly be? It's 2:00 a.m. on a Friday. Nobody is deploying code right now." I go in and workers are crashing. I debug it down to this catch block here. I go and look at GitHub to see when this was committed, and it had been put in the code base two weeks ago. Only just now were events coming in triggering this uncaught exception, because the response here is not defined.
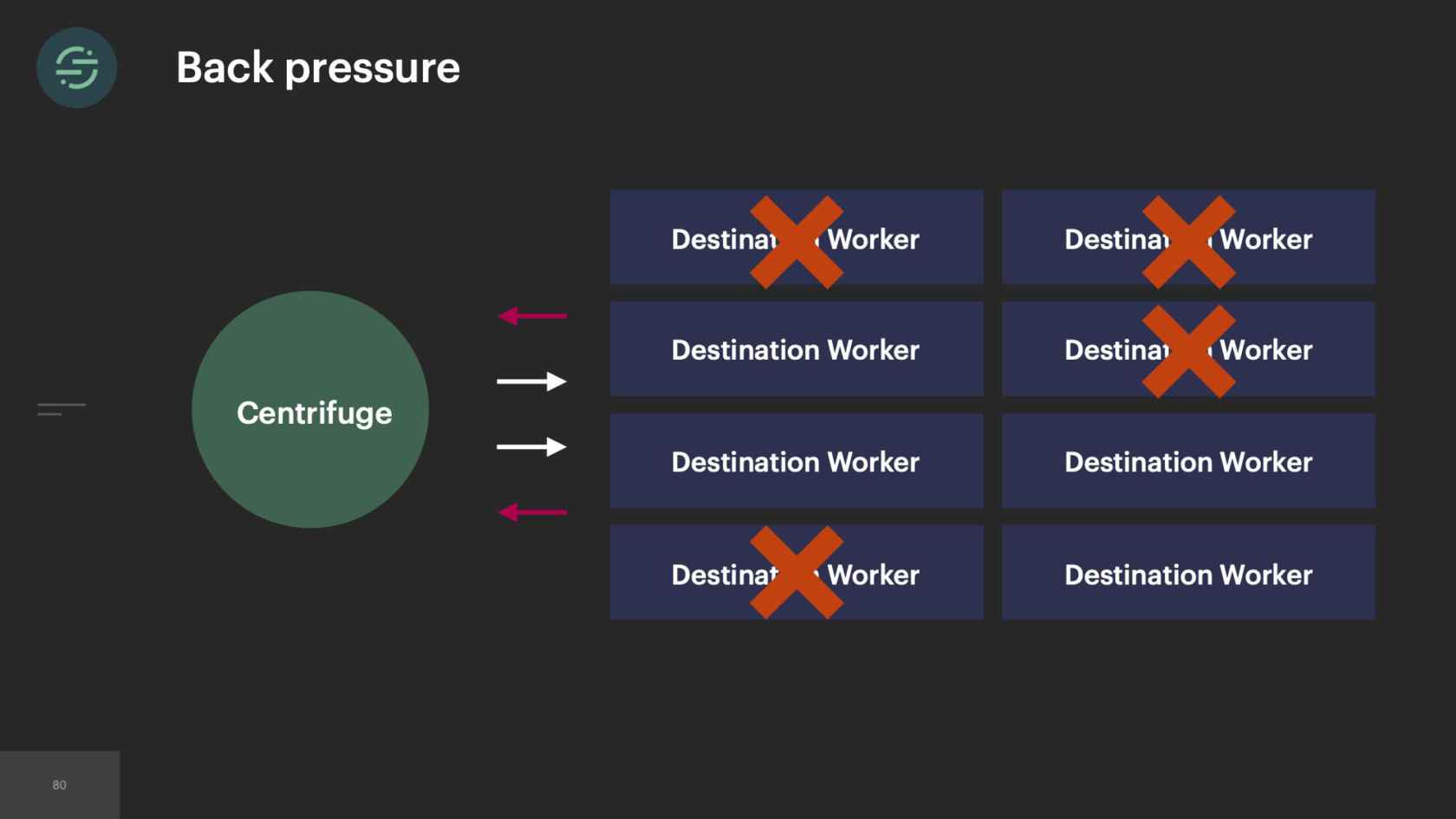
What happens with an uncaught exception in Node is that the process will exit, which causes one of these workers to exit. When one of them exits, this event is considered failed and Centrifuge will actually retry that event. When there are multiple events that are coming in and hitting this code path, we see this cascading failure because now new events are coming in causing these uncaught exceptions, causing these workers to exit. Then Centrifuge is retrying those events causing those workers to exit. We host these workers on AWS's ECS platform. ECS will bring up a new worker whenever one exits, but not at a fast enough rate with how quickly they're exiting here. We also have found that when workers have a really high turnover like this, ECS will actually stop scheduling new tasks to come up. Now we're in the situation where our worker pool is quickly shrinking, but we're sending it more traffic because of all the retries. Then that creates this back pressure situation where every customer and destination is impacted, which should sound a bit familiar.
What's really interesting is that there was a new engineer on the team. One of the first suggestions that came from them was how about we break all these destinations into their own service? That way, if there's an uncaught exception in one, now, it's only reduced to that destination and those customers. There is some truth to that. It would isolate the destinations very nicely so that an uncaught exception would only impact that destination. We'd already been down that road. We'd already been burned by the operational overhead that came with microservices, all the destinations living in their own service. It doesn't actually solve the root issue here. It really just decreases the blast radius.
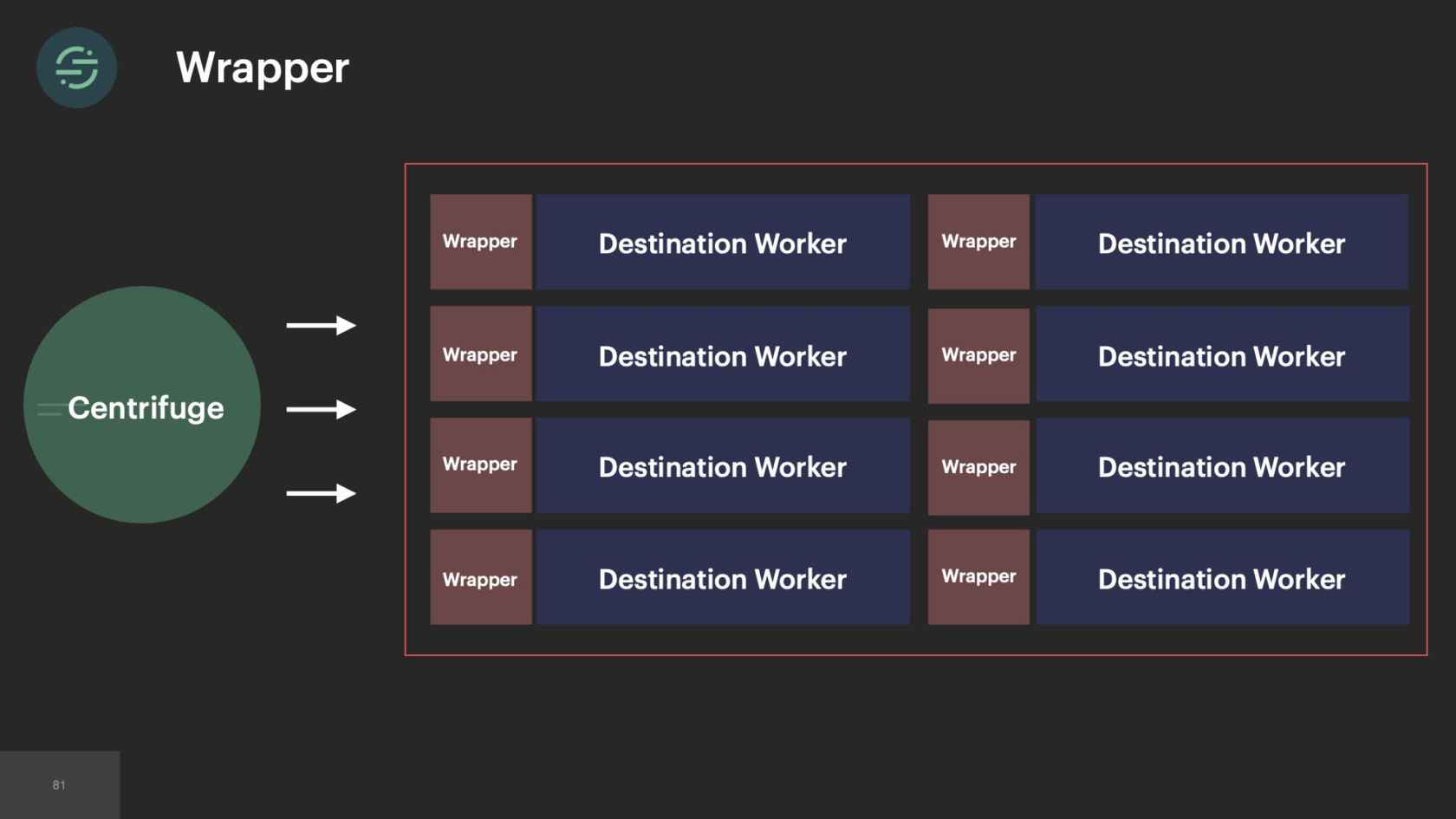
We thought about it a bit more. What we ended up doing was we created a wrapper. How this wrapper works is it's a container runtime that acts as a middleware between the application and the infrastructure. A very simplified version of how it works in the uncaught exception situation is when an uncaught exception happens, it will catch it. Discard it. Then restart the worker. This is really just a workaround, because ECS can't restart tasks quick enough with how quickly they exit. This also doesn't solve the uncaught exception problem. Now at least our worker pool isn't shrinking. We're able to set up alerts and metrics when we have these uncaught exceptions, and then go in and fix them. If you look at the trade-offs again, we've actually made some improvements on our environmental isolation and visibility. We now have the resources and time to build this type of wrapper or to add heapdumps on these hosts.
The Migration Journey
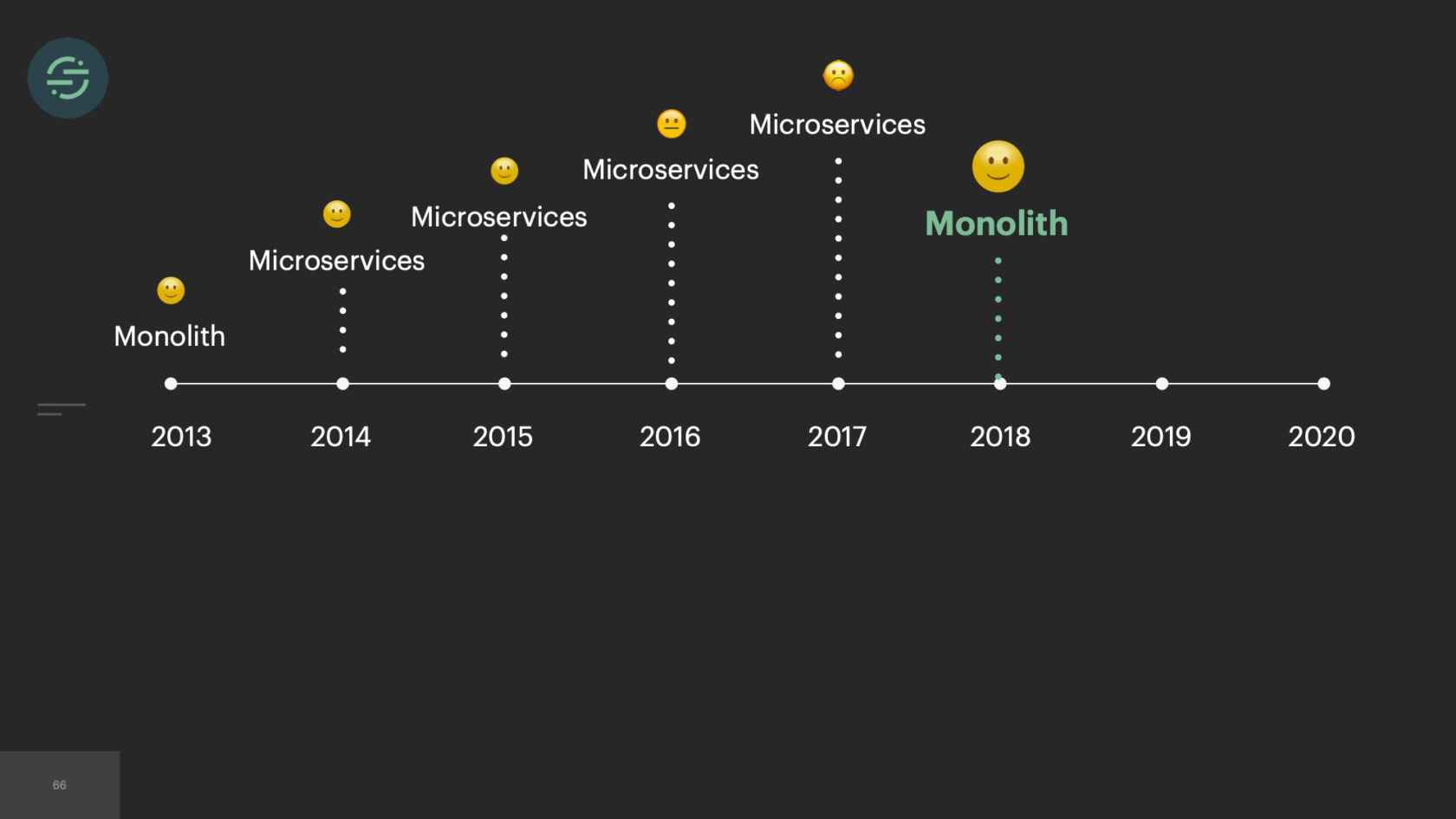
As we've been running into new issues, it's been really interesting to see that almost every time, that our gut reaction is we should break this apart into microservices. It never really solves the root of our issues. I think the biggest lessons that we learned as we moved from monolith to microservices, and then back to monolith is that it's really all about trade-offs, and really understanding the issues that you're dealing with, and making the decision that's right for your team at the time. If we had started with microservices right away in 2013, there's a chance we never would have made it off the ground because of the operational overhead that comes with them. Then we quickly ran into environmental isolation where destinations were impacting one another.
With microservices you get good environmental isolation. We moved to microservices. We had more resources on the team so the operational overhead we were willing to trade off a little bit. It isolated the destinations like we needed from one another at the time. We were having sales deals coming in saying, "You don't support this destination. We need that. Otherwise we're not signing with you." I think when we moved to microservices this time we didn't have a full understanding of what the root issue was. We didn't understand that it was actually our queuing system that was causing a lot of our problems. Even if we did understand this and really took the time to think critically about it, we had only 10 engineers total at the time. I don't know if we would have been able to build Centrifuge that actually solved that problem for us. Centrifuge took us a full year and two of our most senior engineers to get it into production. Microservices provided that isolation that we needed at the time to scale.
Then, after a few years, in 2017, we hit a tipping point and the operational overhead is too great for us. We lacked the proper tooling for testing and deploying these services, so our developer productivity was quickly declining. We were just trying to keep the system alive. The trade-offs were no longer worth it. We now had the resources to really think critically about this problem and fix the system. We moved back to a monolith. This time we made sure to think through every one of the trade-offs and have a good story around each. We built traffic recorder proactively since we knew we were going to lose some of that modularity. Centrifuge helped us solve some of those environmental isolation issues. As we iterate on this infrastructure and are continuing to encounter new issues, we're doing a much better job of really thinking through these trade-offs and doing our best to attempt to solve the root issues that we're dealing with.
Takeaways
If you're going to take anything away from this talk, it's that, there is no silver bullet. You really need to look at the trade-offs and you have to be comfortable with some of the sacrifices that you're going to make. When we move to microservices, and whenever it's suggested again, it's never really solved the root of our problems. When we first moved, it only decreased the blast radius. Then those problems came back to bite us later, but we're much bigger. Nothing can replace, really critically thinking about your problem and making sure you weigh the trade-offs and make the decision that is right for your team at the time. Other parts of our infrastructure, we actually still use microservices, and they work great. Our destinations are a perfect example of how this trend can end up hurting your productivity. The solution that worked for us was moving back to a monolith.
See more presentations with transcripts








































Community comments
Great talk!
by Deepak Garg, May 31, 2020 03:38
CI/CD
by Dmytro Gokun, Jun 14, 2020 07:28
Interesting talk
by Calvin Liang, Jun 19, 2020 04:08
Hats 0xfff, or what ever there needs to be
by Anit Shrestha Manandhar, Dec 18, 2020 08:43
Great talk!
by Deepak Garg, May 31, 2020 03:38
Your message is awaiting moderation. Thank you for participating in the discussion.
Interesting insights
CI/CD
by Dmytro Gokun, Jun 14, 2020 07:28
Your message is awaiting moderation. Thank you for participating in the discussion.
Do not troubles updating sharing libs point to the lack of proper CI/CD & integration tests? It would be the same problem with a monolith. Am I missing something?
Interesting talk
by Calvin Liang, Jun 19, 2020 04:08
Your message is awaiting moderation. Thank you for participating in the discussion.
Interesting talk. It feels like a design problem rather than microservice v.s monolith problem tho.
Imagine we are using logstash + elasticsearch. The microservice architecture feels like spinning up one elasticsearch instance for each logstash worker.
Hats 0xfff, or what ever there needs to be
by Anit Shrestha Manandhar, Dec 18, 2020 08:43
Your message is awaiting moderation. Thank you for participating in the discussion.
This is one of the best story I have heard about the evolution of a system.